
[独立软件分享] 视频字幕自动化制作软件 VoxScripts
thundernet8 · thundernet8 · 2024-03-16 21:43:40 +08:00 · 3262 次点击这是一个创建于 375 天前的主题,其中的信息可能已经有所发展或是发生改变。
关于软件
VoxScripts 字幕机是一款专注于自动化视频转录文本、字幕制作、字幕翻译和配音的桌面软件。借助最新的 AI (人工智能)技术组合,可以低成本并高效地将任意语言的视频、音频转录并翻译为目标语言,适用于多种学习、工作、娱乐场景,如英语学习、外语慕课视频观看、外语生肉剧集综艺抢先观看、视频翻译搬运。软件的视频文本提取使用了本地化模型,带来一些优势,例如更好的个人媒体隐私保护、可以应用自有设备的高性能显卡。
目前软件已经实现从视频到声音提取(基于 FFMPEG ),声音转录为文本(基于 Whisper 本地化模型),文本翻译为多语言(基于 ChatGPT ),文本的语音合成(基于 Edge-TTS )全套流程的自动化和批量化。 以上过程的每一步其实都有多种备选,例如翻译可以用 DeepL 、谷歌翻译,语音合成可以用 MyShell 开源的 TTS 。软件开发的初衷就是将这些组合尽可能低成本的包装交付到用户,未来也会增加各个步骤的替代选项供用户选择。
下面是一些软件截图和导出视频效果图

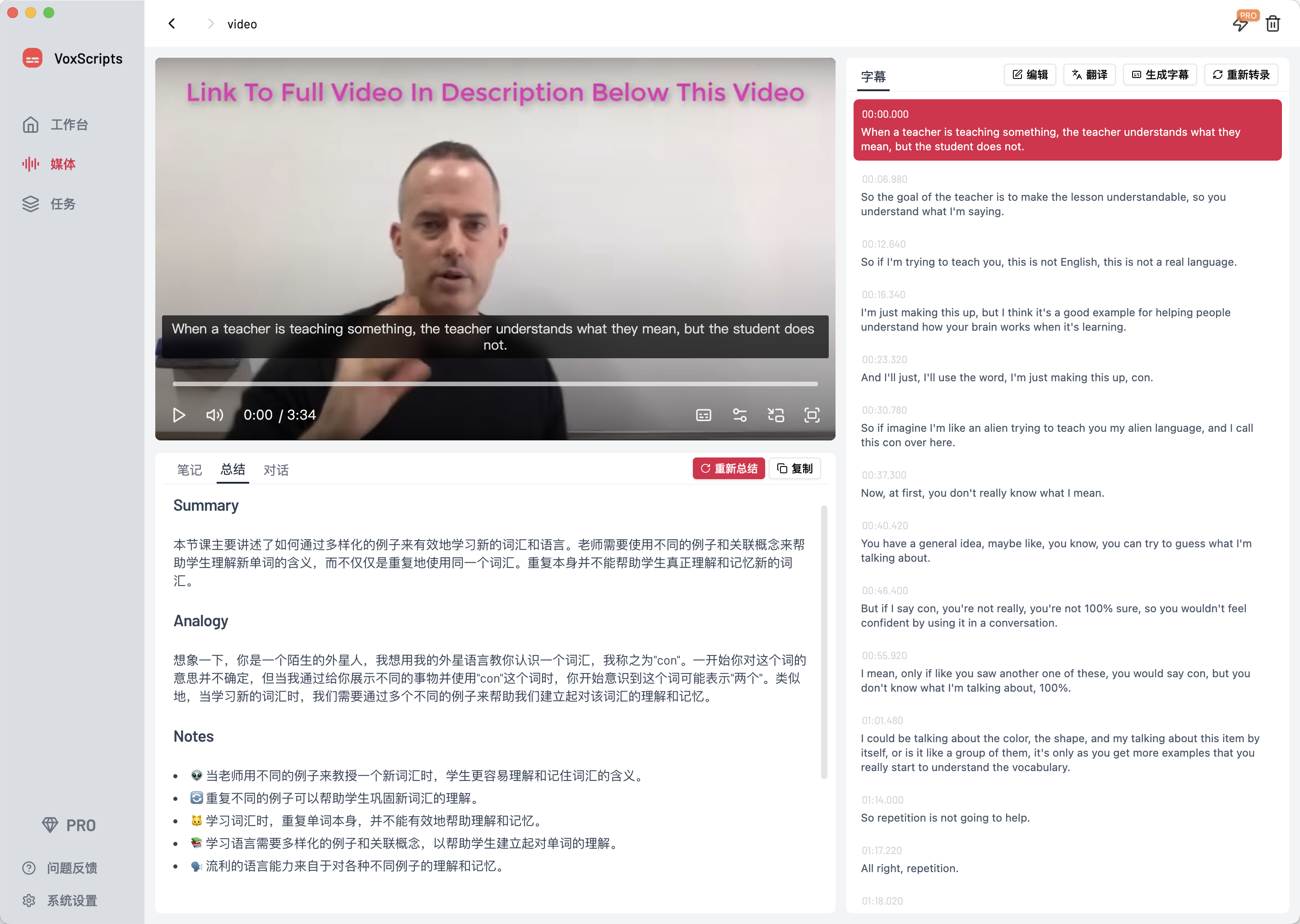
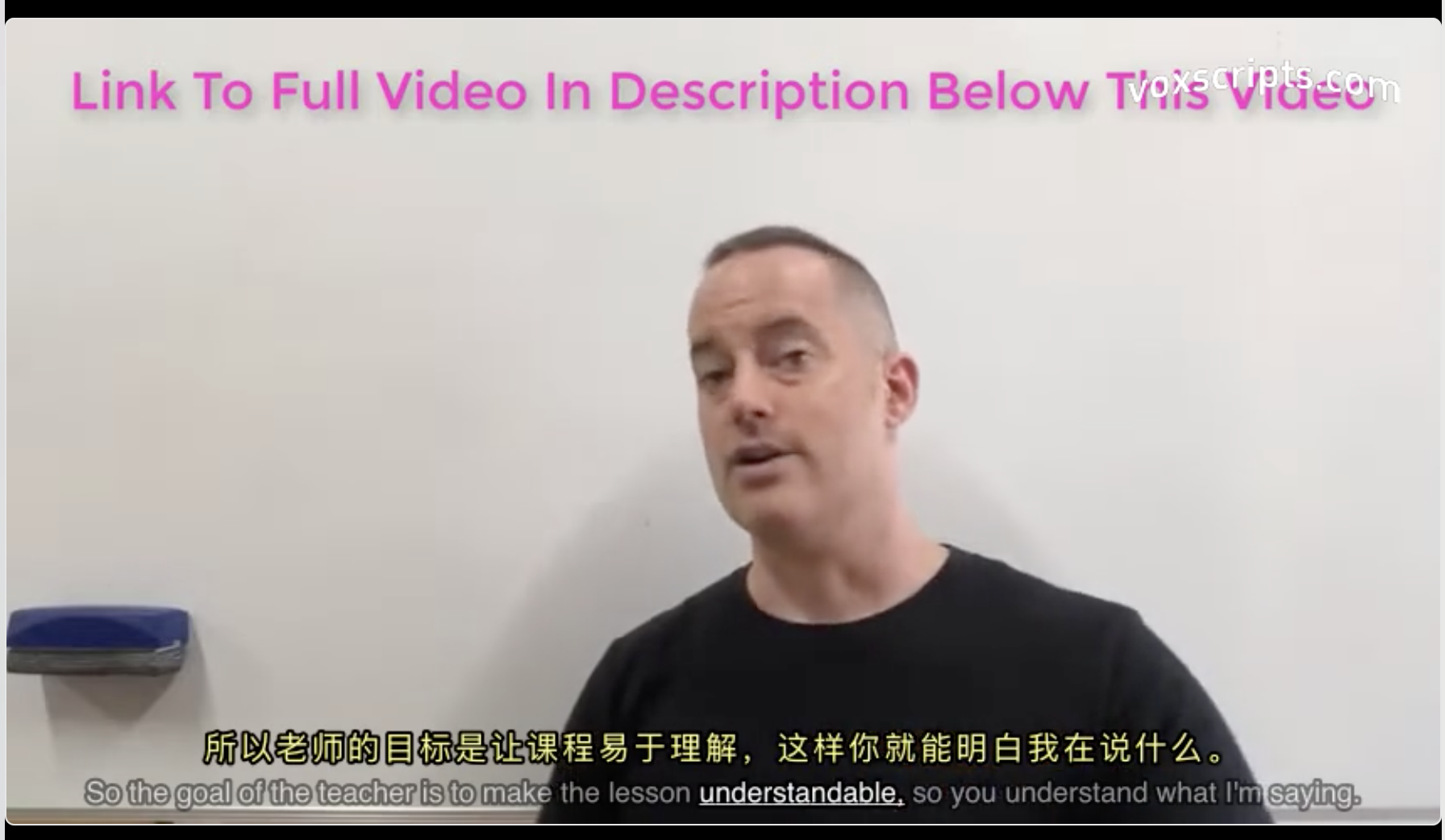
一些开发经验
从去年下半年就有的软件想法,从调研到开发到最小可用版本的完成都踩过坑,解决一些通用问题。 在语音转录为文本方面,希望使用本地模型处理,所以使用了 OpenAI 开源的 Whisper 模型。由于软件是基于 Electron 开发的,最早选型了 C++编写的 Whisper 实现whisper.cpp,通过 NAPI 包装成 NodeJS 原生模块,直到开发跑通了流程,才发现一些不满足需求的地方,特别是必要的单词级别时间戳生成,所以又转向到了 Python 版本的 Whisper 实现fast-whisper。在解决跨语言调用方面,是通过 Pyinstaller 打包 fast-whisper 为一个可执行文件,通过 NodeJS 子进程调用以及 stdout 传输数据。当然 whisper.cpp 还是存在一些优势的,特别是 Mac 平台可以基于 coreML 实现加速。 Whisper 的模型基本来自国外的 HuggingFace ,在国内下载是基本下载不了的,所以这里采用了两种策略,一种是对于小模型,提供了基于 Cloudflare 的 Worker 写了一些中转下载脚本,下载几百兆以内的模型速度还比较不错。另一种是对于大模型,自己下载存到网盘供用户下载,软件提供模型导入的功能。
转录文本的断句方面,Whisper 本身很容易在一句话中间断句,这个很容易造成后续翻译因上下文不连贯而词不达意。在这里软件改进了一下 Whisper 原始转录语句的断句,同时基于单词级别的时间戳信息,在调整断句后仍然可保持精准的字幕时间戳信息。这里的断句优化主要基于句子结束符合的识别,例如中英文句号。在中文语音场景下,Whisper 又很容易不附加句号到语句结尾,导致断句优化方案失效,这里软件的解决方案是利用 Whisper 的 initial prompt ,附加一句语句风格案例,如"从现在开始,我们将讲述一些具体的案例。"( Whisper 的 prompt 和 GPT 的 prompt 不是一个类型的东西,前者是固定提供案例让后续去模仿,而后者可以在 prompt 中语义化赋予指令)。
ChatGPT 翻译上,采用了多句翻译的模式,通过 prompt 让 GPT 返回每一句翻译的数组,该 prompt 也来自推特博主宝玉。优势是省 token 、效率更高,上下文联系多会提高翻译质量,缺点是有时会出现翻译句子合并,比如英文是两句,但是中文一句就翻译完了。对于该问题我已做了一些策略优化,首先是前面提到的断句优化,能够减少翻译合句的几率,另外在有合句的情况下,调整翻译字幕的时间戳覆盖原始多句的开始和结束时间,这样在字幕展示时,翻译语句能够持续到原始语句结束,最后提供选项调整一次翻译的连句数量,降低数量比如调整到 1 可以避免该问题。
语音合成方面,由于不同翻译的句子文本长短不一和 TTS 说话人的语速不一,造成合成句子的播放时长比原始句子的时间范围要长,这在做视频的语音替换时,由于视频的长度不变,合成语音容易出现溢出时间范围和不对齐的问题。这里我采用了两个策略,一是尽量复用原始语句之间的空白,可以作为翻译语句的预留空间,二是通过计算原始语句的长度以及新翻译语句播放长度,调整合适的加速播放速率,确保播放总时长不超过原始可用时间空间。
关于独立开发
虽然是半路前端出身,但我个人是一个偏向全栈的工程师。软件本身、授权服务、官方网站均独立完成设计、前后端开发。在技术栈上前端使用了 React/NextJS ,样式使用 tailwindcss ,以及 copy paste 理念的 shadcn ui 的组件库,开发网站的效率可以说是非常之高。接口基本使用 golang 编写,风格统一、没有语法糖,跨平台编译独立二进制文件,都非常适合我的胃口。
最后
如果您对 VoxScipts 软件有任何兴趣、意见,可以访问软件官方网站 https://voxscripts.com ,或查看软件文档 https://voxscripts.com/docs ,欢迎体验分享以及提出建议反馈。如果您对媒体转录、语音合成、字幕制作、FFMPEG 、独立开发等主题感兴趣,可以扫码加入交流群。
软件官方下载地址: https://voxscripts.com/download
惯例,软件激活码福利附上:
- 120217-E441EA-467E8C-31D804-1D2A83-V1
- 1A1AFF-49AE51-46099F-90C728-96DFB9-V1
- 2C5B9A-4CA793-42E88E-2495D5-8F927A-V1
- 7D1D6E-E1900E-43A790-8D7EA0-69B5D4-V1
- 4991BA-866998-4B5984-E5C3E3-B89F26-V1
- 0FC946-135930-47E89B-1AC35A-23D7BA-V1
- B939BC-A71F8D-403694-B54601-41521F-V1
- 8E5C7A-18A4E0-450592-DF897F-E8065B-V1
- 7B0800-D171FD-4CCEBA-15160C-6E72CB-V1
- 5B5777-2345A7-442282-6343B0-B8C720-V1
16 条回复 • 2024-03-22 12:59:46 +08:00
 |
1
tsukiikekaoru 2024-03-16 22:44:20 +08:00 via iPhone
5B5777-2345A7-442282-6343B0-B8C720-V1 已用。看下来软件还处于比较早期的版本。mac 版无法激活,很多地方点击都没反应,不知道是不是电脑硬件比较老旧的原因,系统是 10.15 。另外有个类似的软件 memo ai 不知道作者是否了解,从描述看这两个软件拟解决的问题几乎一摸一样,技术路线也是一样,后者目前还更完善些,不知道作者打算如何做出差异化
|
 |
2
emberzhang 2024-03-16 23:53:48 +08:00
8E5C7A-18A4E0-450592-DF897F-E8065B-V1 已用谢谢。我这里 Sonoma 14.4 看起来正常激活了
|
 |
3
oneisall8955 2024-03-17 00:04:37 +08:00
本地软件开能使用激活码,暂时没有电脑在身边呢
|
 |
4
youngteam99 2024-03-17 06:08:30 +08:00
5B5777-2345A7-442282-6343B0-B8C720-V1 Windows 可以激活 谢谢
|
 |
5
RJR916 2024-03-17 09:38:36 +08:00 via iPhone
晚上回去试试
|
 |
6
Downstars 2024-03-17 11:53:46 +08:00
4991BA-866998-4B5984-E5C3E3-B89F26-V1 windows11 可以激活 感谢
|
 |
7
thundernet8 OP @tsukiikekaoru 感谢反馈。目前软件本身确实是比较早期的不完善,然后针对竞品的问题,我目前理解软件大概有三个方向,一是强化字幕制作工具的能力,能够匹配一些传统字幕制作软件,这个因为比较容易明确交付什么,客户需要什么也比较明确,因此倾向性较高,二是针对语言学习、课程学习场景,这里的需求对用户来讲其实自己都不明确,所以产品定义上就更难明确,所以倾向性较低,三是针对以媒体为起点的内容创作者,希望整合 RPA 来提高内容创作效率,这方面容易对用户交付价值,所以有一定的想法去研究
|
 |
8
lamquan 2024-03-18 06:45:53 +08:00
120217-E441EA-467E8C-31D804-1D2A83-V1 已用,还没顾上详细试用。但楼主在转录、翻译和合成上的考虑确实都是难解决的问题,虽然现在大模型都有,但在具体问题上还有很多问题要解决。期待……
|
|
9
lamquan 2024-03-18 14:19:03 +08:00
试了一下,windows 平台,下载 youtube 视频成功,下载 large 模型成功,但是转录没有结果……
|
|
10
thundernet8 OP @lamquan 模型较大时,需要使用 GPU ,而且显存 4g 都比较勉强,建议 6G+,或者使用 medium 以下尺寸模型
|
 |
11
lizhenda 2024-03-19 00:02:26 +08:00
没有百度网盘会员,下载速度感人 ...
|
|
13
thundernet8 OP @lizhenda 感谢反馈,考虑增加下载渠道
|
 |
14
VictorFrank1 2024-03-19 17:14:32 +08:00
M1pro 芯片的电脑能带动吗?(好奇那个笔记功能是像 Anki 那样吗?选中单词然后索取上下文重复记忆)
|
|
15
thundernet8 OP @VictorFrank1 现在还没支持 M 芯片
|
 |
16
leeyuky 2024-03-22 12:59:46 +08:00
@thundernet8 whisper.cpp 都已经支持神经网络引擎 inference 了,你们也不跟进一下
|