
这是一个创建于 3394 天前的主题,其中的信息可能已经有所发展或是发生改变。
今天是数人云容器三国演义 Meetup 嘉宾演讲实录第二弹。数人云工程师春明为大家奉送了一盘干货的大餐,让我们读读源码,深入了解一下 SwarmKit 的世界吧!
小数前方预警:有大量代码出现!

今天与大家分享一下数人云对于 SwarmKit 的尝试和探索。 Swarm 早在 2014 年就出来了,和 Docker Compose 几乎是同一时期。 Docker 解决的是单机上容器的问题,但如何在一个集群一组的硬件资源上去调度容器? Swarm 可以解决。 SwarmKit 是在 Swarm 的基础上研发出来的,只不过 Docker 公司对 SwarmKit 联系得更紧密。 SwarmKit 的主要代码提交在 2016 年 4 、 5 月份, Docker1.12 出来以后正式把它 release 出来。
我个人比较看好 SwarmKit 的原因在于它很简单。在生产环境部署 Mesos 或者 Kubernetes ,需要安装的组件非常多。 Mesos 为例,首先要装 Zookeeper ,然后装 master 、 slave ,它们之间配置、连线都很复杂,更不用说每条连线后面大量的工作,最终 cluster 才能跑起来,并且有很复杂的 API 。相比而言, SwarmKit 非常简单,一个 Binary 解决所有问题。
今天分享的第一部分会和大家说一下什么是 SwarmKit ,第二部分聊聊 ServiceScheduler ,从一个程序员的角度思考如何构造一个调度器。这个调度器, Service Scheduler ,类似于 SwarmKit 、 Kubernetes 、 Mesos 加 Marathon 。第三部分通过几段代码片段了解 SwarmKit 的关键点。
SwarmKit 的概念
SwarmKit 、 Swarm 、 Swarm Mode 这三个词,对刚开始接触的人来说可能有很多困惑。 SwarmKit 是 Swarm 这个项目的升级版。 Swarm 和 SwarmKit 最主要的区别在于 Swarm 是单独运行的,它需要一个第三方的分布式存储,它支持三种存储方式,即主流的三种分布式存储—— Zookeeper 、 ETCD 和 Counsul 。
SwarmKit 在 Swarm 的基础上精进了一步,不再需要有第三方存储,也不需要做 Leader 选举。它的发布方式,一种是独立的,另一种是直接和 DockerEnginet 混搭放在一起。所以大家安装新 Docker1.12 版本之后,实际上也拥有了 SwarmKit 。你有多台机器安装了 Docker1.12 版本,就已经拥有了一个 Swarm 的 cluster ,在上面就可以把任务负载到不同的机器上,不需要再去安装一堆组件。另外一个词叫 Swarm Mode ,如果你开启了 Swarm 模式的 Docker Engine ,用 Docker 的集群功能的时候 ,它实际上就是进入了 Swarm Mode 。
构造服务调度
接下来聊一聊从一个程序员写代码的角度理解如何去构造一个 Service Scheduler ,服务调度。程序员其实不太关心底层的硬件资源或者 Saas 层是怎么来的,更多是考虑如何实现一个任务或者一组任务去分发、放在不同的一组机器上。如果想做好这个事情,无论是公有云、私有云或者虚拟机,首先要做的应该是把所有的资源进行抽象。如果是 Mesos Framework ,第一件事情是去 Mesos 申请一块资源,不用关心资源到底来自于哪里,你申请一个 offer 、要两块 CPU 或者 200M 的内存, Mesos 如果满足你就会反馈 OK ,如果满足不了你就告诉你等一下。首先把一组资源抽象,比如池子有多少个 CPU 、有多少内存,把它抽象。第二步分配,如果有一个请求过来,就从池子里面分配资源,然后 release 。
服务可能分很多个进程,最终负载在不同的机器上。第二部分,是对服务这个概念上有一个抽象,服务应该有它的生命周期、健康检测。服务下面应该有不同的进程,这在不同的 Service Scheduler 有不同的叫法,比如 Marathon 把它叫做 instance , Mesos 中叫 task , SwarmKit 也叫 task ,实际上它是一个运行中的实例,包含了刚才从资源池里申请的一块资源,并且有自己的生命周期。其中最重要的应该是健康检查,不同人对一个服务的健康状态有着不同的定义。
以前我们用 Docker Daemon ,那现在如何判断一个服务是不是健康的?在 DockerEgine 加入了健康检测之前,我们主要看它的容器是否起来。一个容器起来,能够对外服务,这时就看下一步的负载均衡、服务发现以及编排。服务之间其实有一个依赖,服务 A 在依赖服务 B 的情况下,只有服务 B 起来,服务 A 才能起。所以这一步很重要,对应用具体的实例抽象,这里面其实是一个状态机,专门做了状态的切换。
第三部分,在做一个服务编排的时候,应该有一定的策略、算法去做服务的分发以及服务的编排。某些服务可能对特定资源有一些特别的需要,比如对网络的需要比较强,对存储、对运算能力可能有一些特别的需求;两个服务之间有一定的亲缘性,比如希望 web 服务跑在离开我更近的缓存上面;服务有几种分类,举例来说, Web 的应用和数据库类型的应用其实有一些区别,数据库类型的应用对弹性的需求没有那么高,而 Web 服务对弹性的需求比较高。所以第三件事情应该是做好这一层面策略以及分发。
第四部分,把一堆服务都分到下面不同的机器上,有不同的分发策略以及不同的网络模型后,如何让服务真正的对外服务?即如何解决服务发现、负载均衡还有 Proxy 这层的问题。市面上服务发现的方案非常多。比如 SwarmKit 通过 DNS 实现, IPVS 也是它的一种。新浪微博提出的 NginxModule 以及更早期的一个开源项目叫 Bamboo ,一个刷 HA 的工具,如果容器的状态有变化,它会通过 Bamboo 去刷 HA 的配置,最终把 HA 重启。还有 Registratorr 、 confd 、 Counsul Template 等一些项目,其实都是着力解决服务发现、 LoadBalance 以及 Proxy 。
对于服务发现, DNS 、 SRV 、 IPVS 都是非常好的解决方案。它们有不同的应用场景,比如 IPVS 倾向于四层的负载均衡。 DNS 不单是负载均衡,它同时解决了服务发现和负载均衡两个点。
我们的场景非常需要 Proxy 层,对它有很多期望:比如流量分发、限制、统计以及灰度发布等。最近我做的一件事情是在所有的应用前面加一层 Proxy ,大家可以理解为一层 Nginx 或者是一层 HA ,但实现 HA 这种性能其实是很难做到的。
如何做好一个 Service Scheduler ,除了上述几点,接下来几个方面也很重要。第一, HA 的需求,即客户对 ServiceScheduler 的高可用性的要求,数人云有很多金融方面的客户,他们对 HA 要求更高,比如提到的“两地三中心”,归根结底是 HA 的需求。
第二个,安全方面, SwarmKit 支持分布在不同的地方,那么解决安全的问题就非常重要。 Docker 的安全问题很严重,因为实际上 Docker 给外部的人有权限去执行任何程序。
解决 HA 问题无非是要布多个,布单个可能有单点的问题。 SwarmKit 从中借鉴了很多,它把 Mesos 的几个部分合在一起,这就引出一个问题,比如它要记录状态,那么如何在一个分布式的环境下去记录这个状态,分布式的存储。

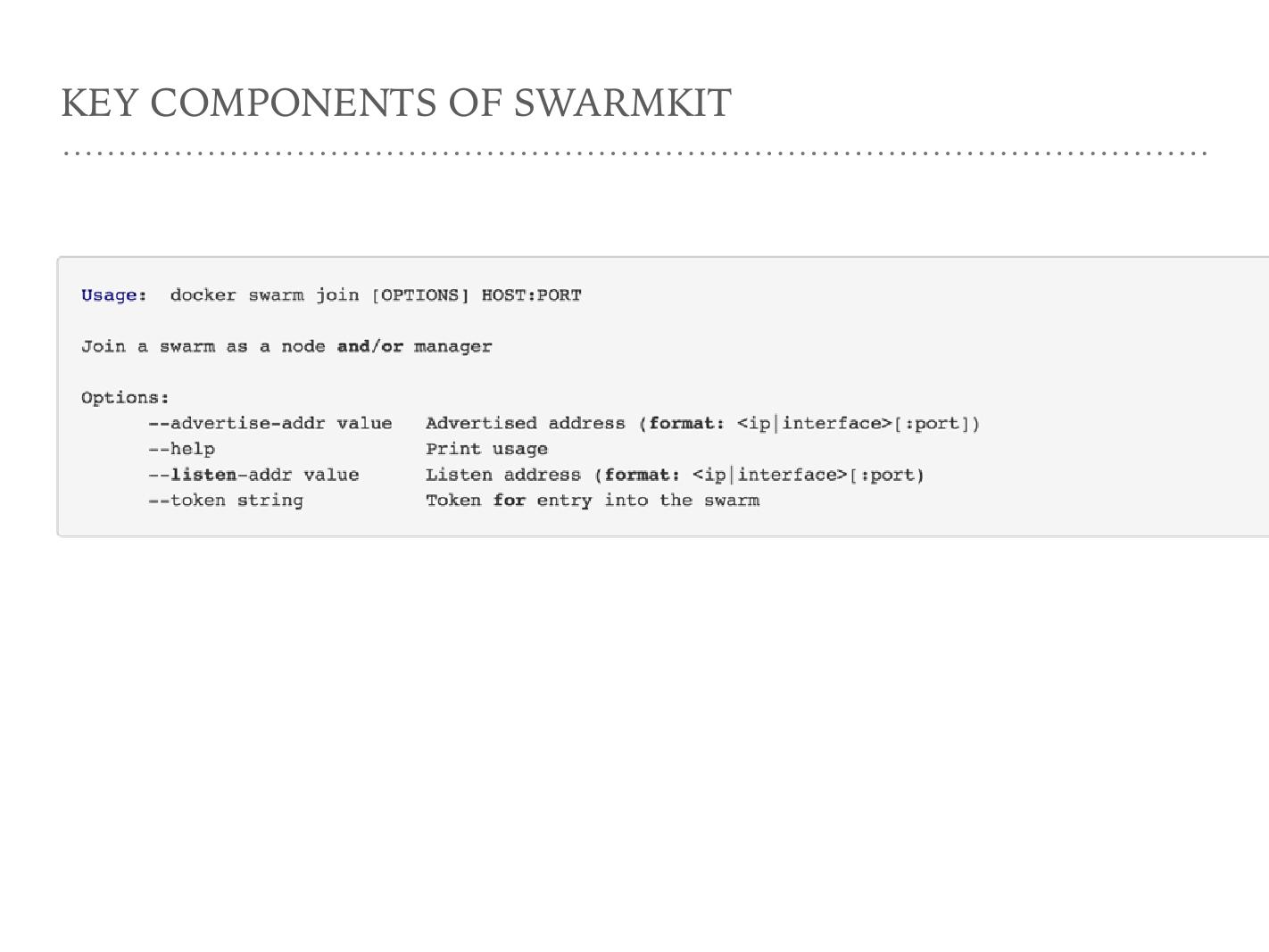
这是开启一个 SwarmKit 的管理节点的一行命令,相当于安装一个 Mesosmaster 和一个 Zookeeper 。第二个命令是把当前 Docker agent 加入到一个 Swarm 集群里面,相当于装了一个 slave 的节点。刚才这两条命令其实就构建了一个两节点的 Swarm 集群。
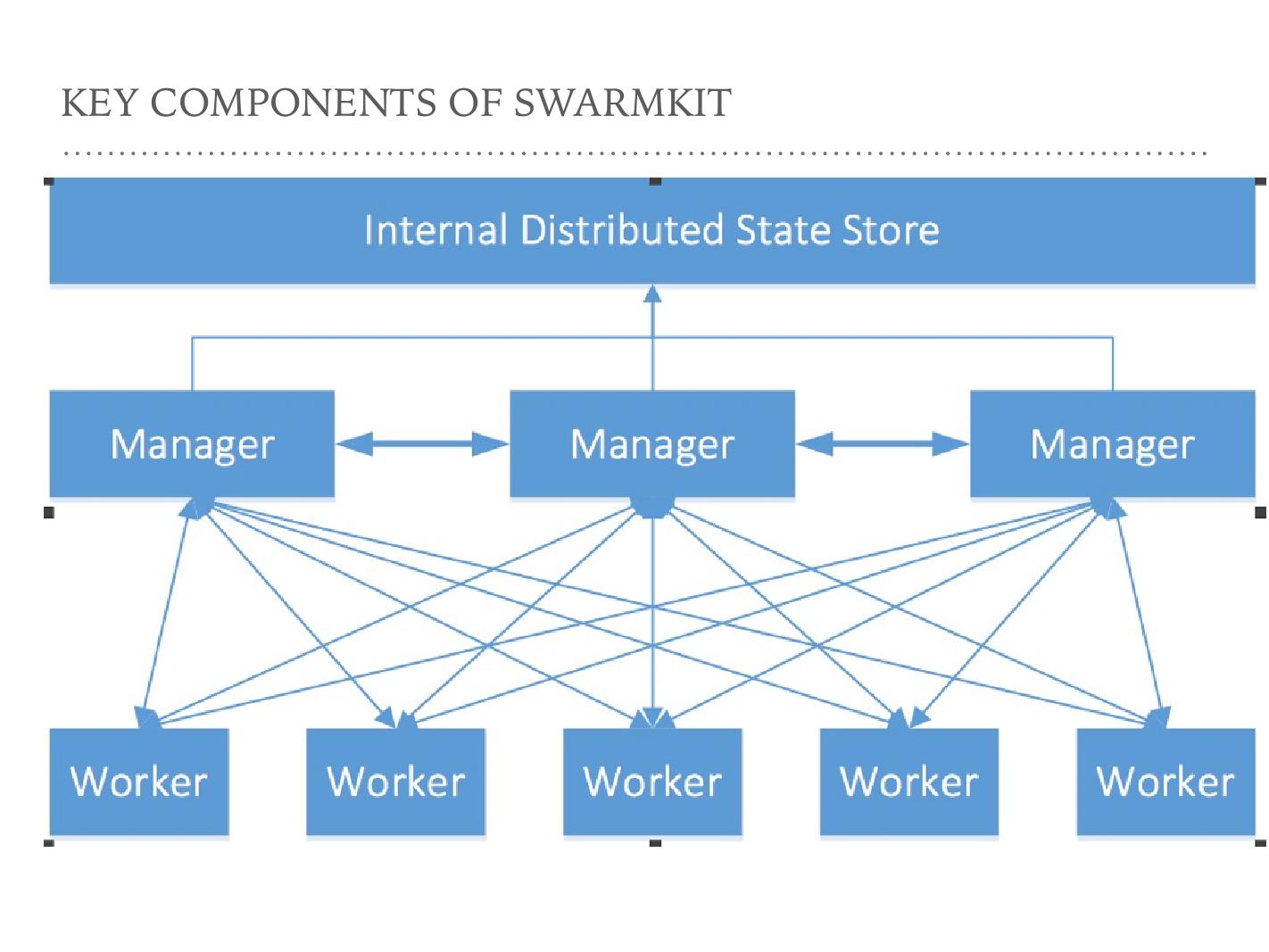
这张图描述了 Swarm 的工作模式。有三层,这是一个二进制,它们充当不同的角色。这些线彼此连接,可以看到 Manager 和 Manager 之间是可以交互的, Manager 和 Worker 之间也可以交互。 Manager 和 Manager 节点之间交互是 raft 协议在做 Leader 的选举,和 Worker 之间的这条线表示把一个任务分发到不同的 Worker 上。在 SwarmKit 里面, Worker 换了一个名字叫叫 agent 。 Worker 听起来像纯粹干活的东西, agent 则还能做一些其它事情,比如做健康检测、做主机、主机资源的收集。
在图上大家会看到每一个 Worker 和三个 Manager 同时通信的,但事实上不是这样, SwarmKit 在同一时间只和 raft 选举出的一个 leader 去交互。
SwarmKit 的关键组成
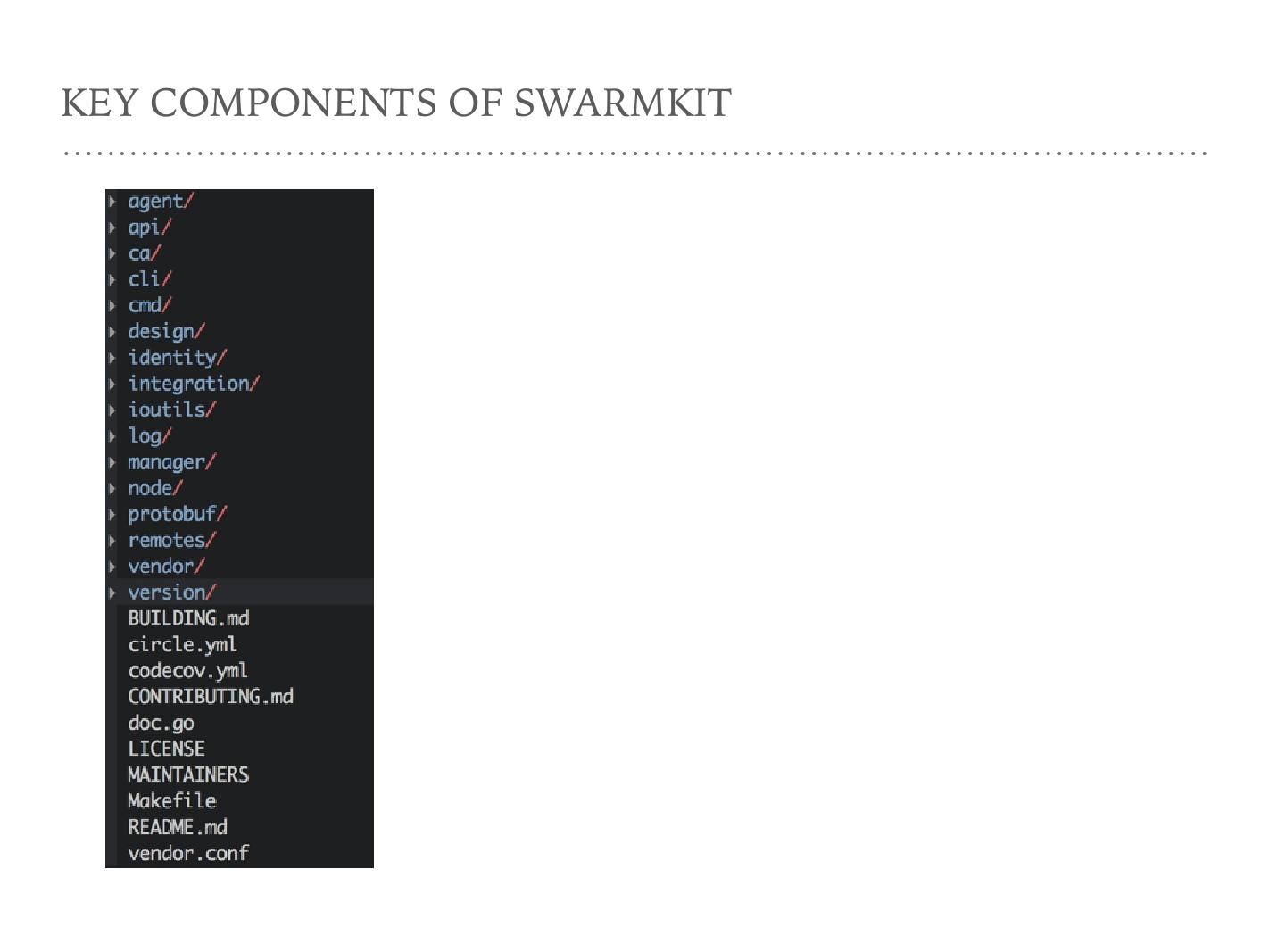
接下来展示 SwarmKit 的代码结构,来了解它们各自的工作。第一个是 agent ,即刚才说的 Worker ,它做的事情是 SwarmKit 节点作为 agent 的时候要做的事情,代码写在 agent 这个地方。第二个是 API , API 不是通过 HTTP REST Service 或者通过命令行跟它交互, API 实际上是 Manager 和 Worker 之间交互的那些命令,它用 gRPC 协议,通过 protobuf 协议来交互。第三个目录叫 CA , CA 解决安全问题。 SwarmKit 号称安全做得很好,它的公钥和私钥可以 ratate ,即它的公钥和私钥有一个过期时间,然后再不同的循环,所以私钥被 compromise 的时候不会影响整个系统的安全性,因为会 rotate 它。 CLI 和 CMD 是操作一个 SwarmKit 时的入口。 design 是设计文档。 integration 是集成。
下面是比较重要的两个文件夹,第一个是 Manager ,和上面的 agent 对应,一个 Swarm node 在充当一个 Manager 的时候,它的逻辑就在这里,即它分发、健康检查及其他代码都在 Manager 上面。另一个是 node 的节点, Docker Swarm init 的时候就是创建一个 node 逻辑的概念,其主要的代码在 node 的下面。
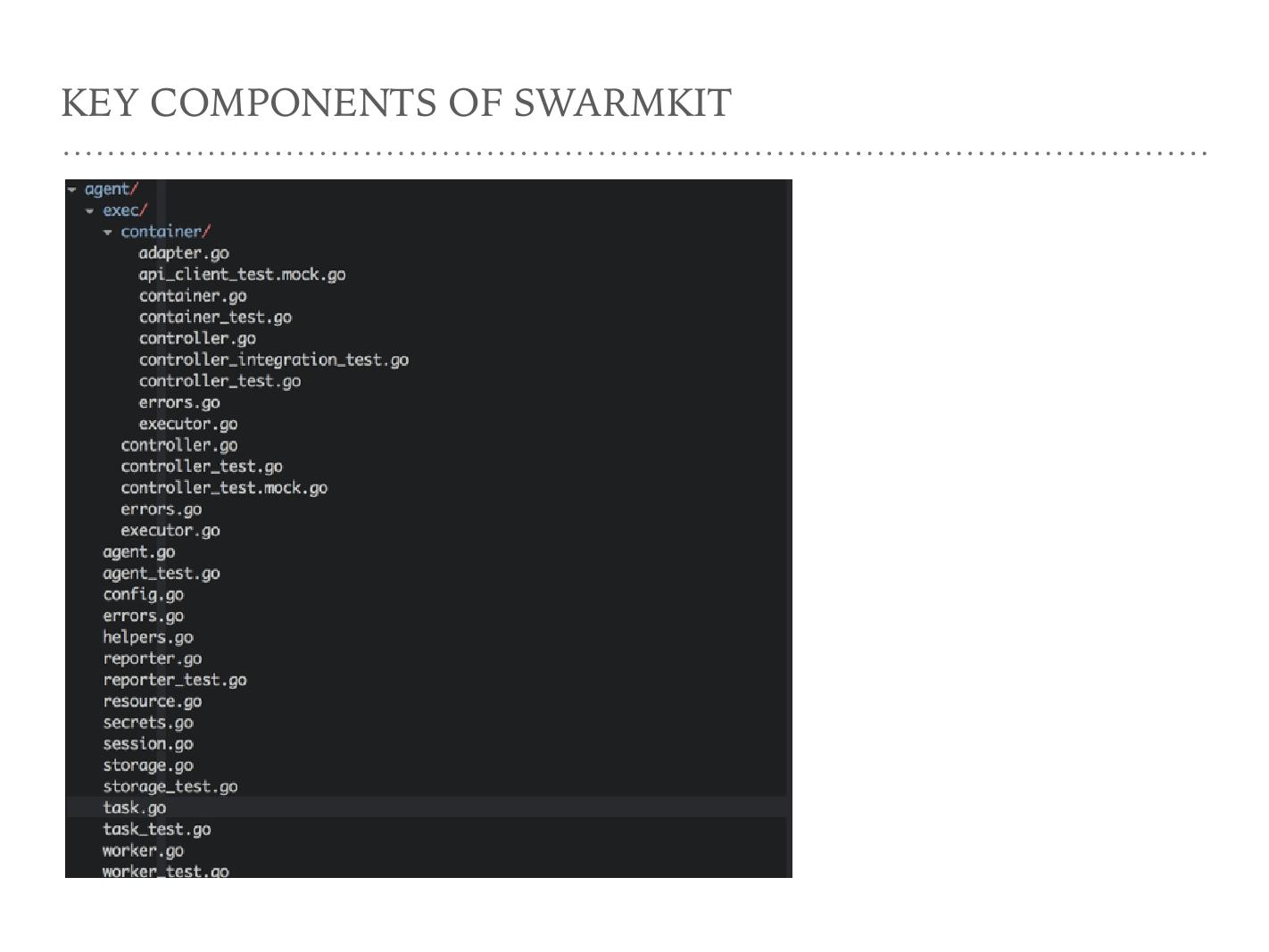
这张截图是打开 agent 的文件夹,介绍一下每个文件分别做什么。第一个是文件夹,这里的核心逻辑, exec 文件夹下核心文件是一个 Docker client 。大家如果用 GoDocker client 会发现里面就是这些——如何维护、连一个 Docker 的 agent 去 update 、 create 、 destroy Docker 的代码。但它使用的是 docker engine-api 的库,而不是 Godocker client ,因为 engine-api 那个项目是 Docker 公司的, agent 的核心代码都在里面。
接下来比较重要的就是 Task 、 Worker 和 Session 这三个文件, Task 是任务的一个抽象。 agent 下面的数据结构里面会包含一个 Worker ,它是 task 真正干活的东西,之后我们会详细的说一说 Worker 。刚才图中看到 Worker 和 Manager 之间那条线用的就是 Session 的抽象。
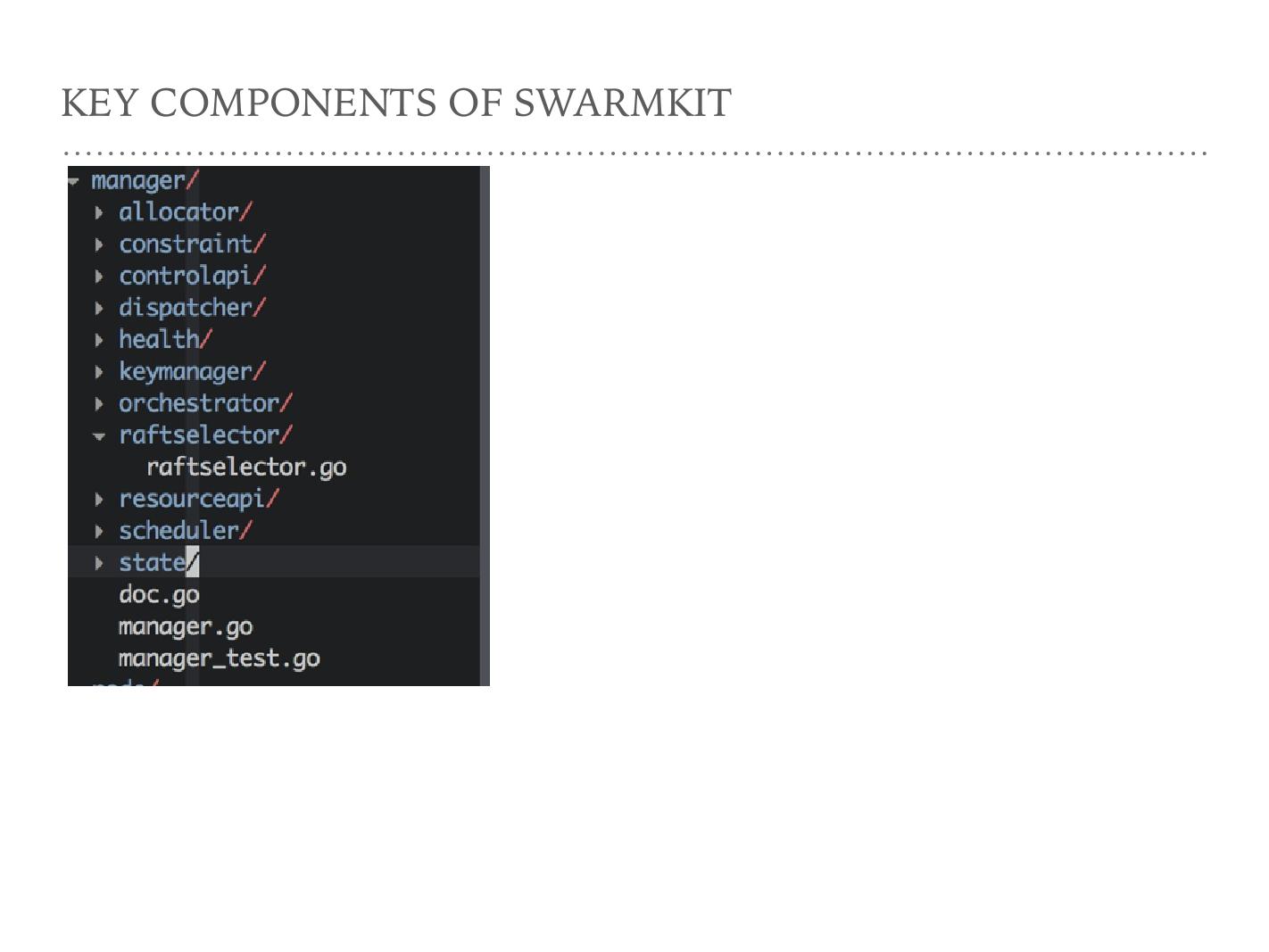
另一个比较重要的文件夹是 Manager 。它的文件夹很多,第一个 allocator 主要是说资源,要申请哪些资源。它里面对网络有一些抽象,从申请上看对 CPU 和 Manager 没有提到,它只是对申请 allocator 有一个网段。 constraint 是有哪些限制,大家如果用过 Mesos 都会知道对任务的开发需要一些 label 满足 SSD 、 memory 等,就是由 constraint 来做。 controlapi 是 alloctator 和外面交互的一个 API 层。下面的 dispatcher 和 orchestrator 和 scheduler 这三个词很难说它们本质有什么区别,只是多少会有一点。 orchestrator 更倾向于 Swarm 的任务,它分两大类, replicate 和 global 的任务, global 的任务在每个 node 上只部署一个节点。 replicate 是传一个数量,然后部署这个数量。
Node

看了整个代码,我总结出了几点核心概念。第一个是 Node 的节点,更确切的说是对 Dockeragent 的一个抽象。然后 Manager 节点。 Manager 和 Node agent 是一个 Node ,它既可以作为 Manager 又可以作为 agent ,或者同时兼有两个。第四个是 Task 和 Service , Service 是我们更高一层对应用的抽象; Task 是一个进程,更确切地说应该是一个容器。 SwarmKit 的 Task 和 Service 都有自己生命周期的定义。
读 SwarmKit 的代码比较好的一点是它入口非常简单,每一个核心的概念里面,一个 new 、一个 run 。 new 是初始化的数据结构, run 是真正的干活。大家如果想快速的了解代码,去每一个概念里面了解这两个函数基本上就知道它们做了什么。

这是 Node 节点的 new 。 Node 的节点最核心的是初始化了一些 channel ,在上面创建了文件夹,这基本是 Node 节点的 new ,但是它的 run 做了很多事情。 run 的函数很长,里面主要做了一些文件夹初始化,以及 SwarmKit 用了一个在 golang 社区比较流行的 DB 叫 bolt DB ,这里主要初始化文件夹和 bolt DB 的初始化。 run 另外一个比较重要的是 Node 的节点, Node 的节点可以创造 Manager 的 role 。 Node 既可以充当 Manager 的 role ,又可以变为 Worker 的 role ,这两个角色可以在运行时动态变化。它们在每次变化的时候,比如变成 Manager ,那作为 Manager 身份的一些功能就开启,由 Manager 变成 agent 这些功能可能就被 disable 掉。
Manager
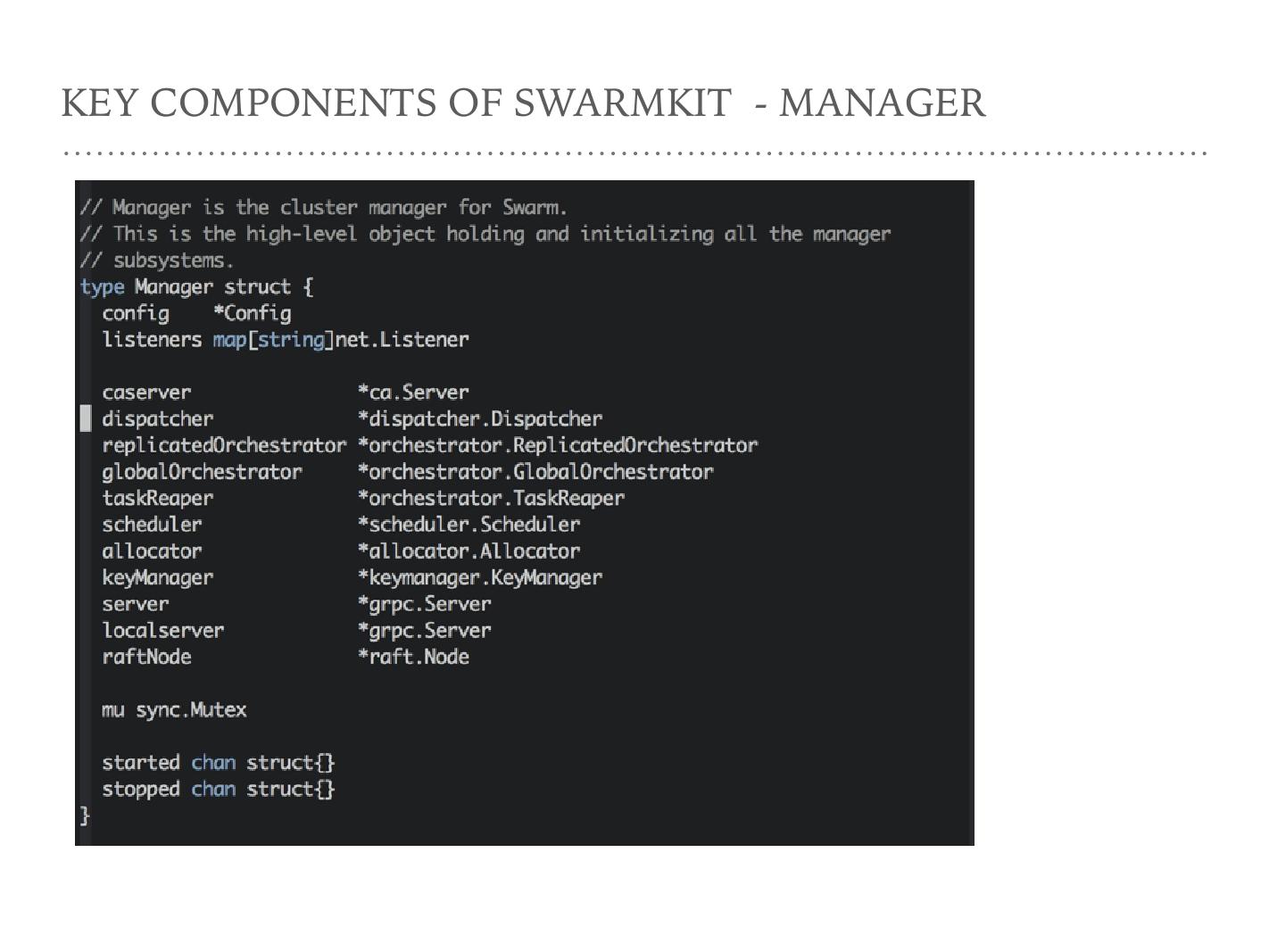
第二个关于 Node 的概念是 Manager ,这是 Manager 的数据结构。比较有意思的是中间这一部分它作为一个 CAserver ,作为一个 dispatcher ,作为一个 replicatedOrchestrator ,或者是作为一个 global Orchestrator 。这些是作为 Manager 功能的数据结构。

此图是 Manager 的 new ,这一屏核心是监听了一个端口,它和 Docker Engine 非常像,监听一个 TCP 的端口,或者监听一个 unixsock 的端口,都是可以的。只监听一个 TCP 其已经满足大部分场景,那么 Docker 、 agent 为什么监听一个 unixsock 的端口?大家关注过 Docker Engine 就会知道,有一个 Docker in Docker 非常适合 Docker 测试。如何做到 Docker in Docker 呢?就是把 unixsock 传到 Docker 里,相当于在一个 Docker 容器里控制外面的那个 Docker 。

这是 Manager new 的第二个 slave ,是 Manager 真正干活的时候,也比较简单,主要是两件事情,第一件事情是作为一个 Manager 节点,监听了 raft 的协议一些 change 的变化,第二是注册了一些 API ,这些 API 是 Manager 节点和 agent 的节点进行交互的一些 API 。
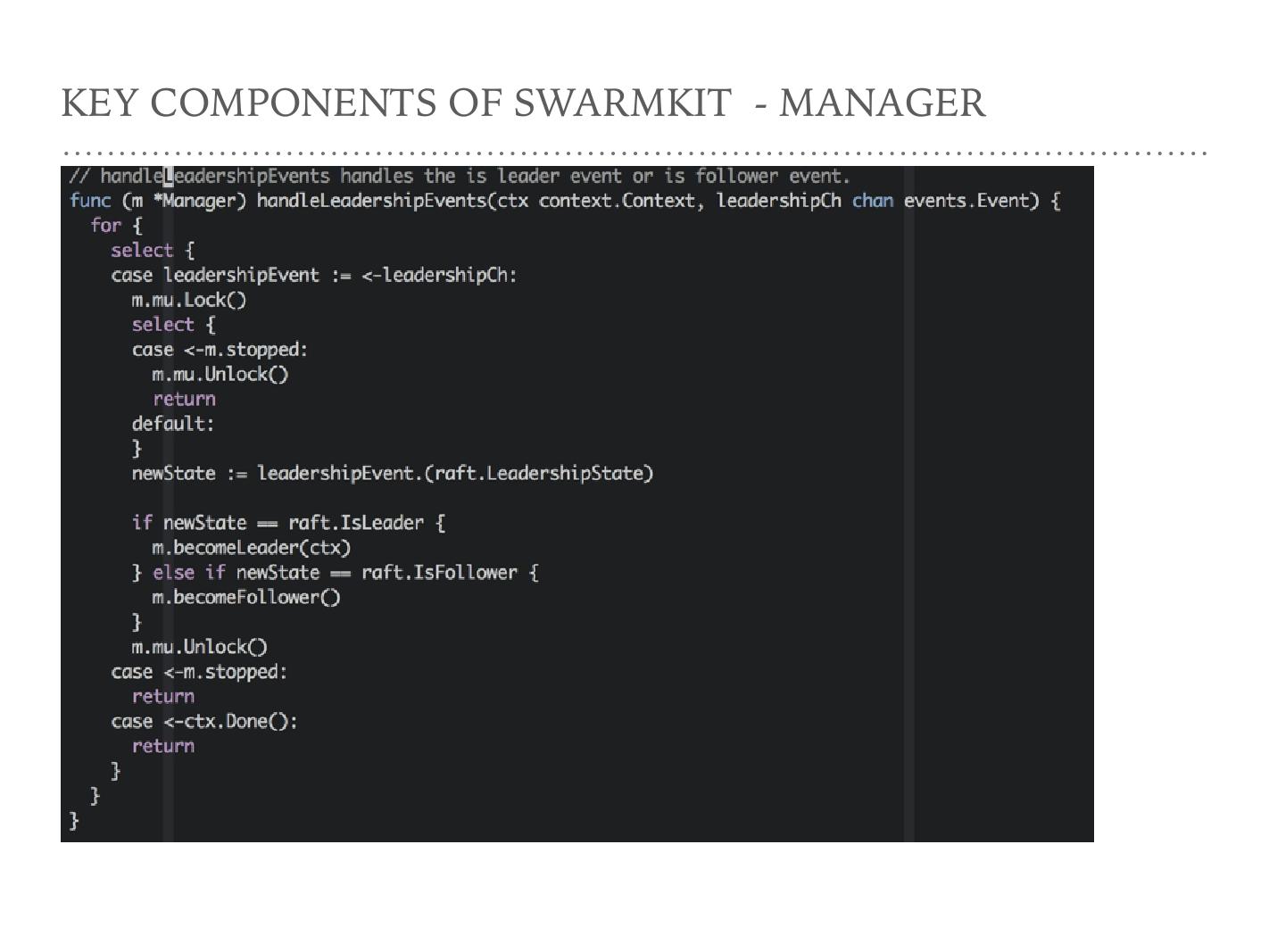
注意一下 handleLeadershipEvents , Manager 实际上是一个小的区别于 Node 的节点,这几个 Manager 节点参与 raft 的选取过程。 Manager 节点最终干活的只有一个,就是 raft 协议选出的那个 leader 。在这个 raft 协议 leader 变化的时候,作为 Manager 节点干的活就不一样了。
在 LeadershipEvents 发生的时候,当前的 Manager 就看一下自己是 leader 还是 follower ,然后根据不同的角色转换去做不同的事情。
Agent

第三个重点是 agent 。之前提到做一个 Node 的 agent 角色的时候,作为 agent 的角色它需要做哪些事情——负责 Task 的分发和执行。 Worker 这边,它作为一个 interface ,在 agent 里则作为 agent 。它作为 interface 给大家一个可能性,即 SwarmKit 这本身可以不只依赖于 Docker Engine 。我见到开源项目有人叫 SwarmKit on Mesos ,只要有不同的 worker 实现,通过 Swarm 底层是可以运行 Mesos 的。 SwarmKit 本身对资源和任务的抽象抽象是固定的。
作为 agent ,其实多了一个 Start , Start 的时候支撑了 run 的函数。核心在于让 agent 下面由 Worker 开始干活,以及维护和 Manager 之间的 session —— agent 和 Worker 之间,比如 leader 的变化、 session 的变化,有 error 都会通过 session 来通知 agent 做一些相应的事情。比如 assign 一个 task 到某个 agent 或者 session 处理一些 error ,大家都可以看到。
还有一个 executer 。 executer 内部是一个 Docker client ,操作 Docker ,实体化一个 Docker ,以及删除一个 Docker 。
Session
session 是 agent 和 Worker 之间线的抽象。底层是一个 gRPC 的的 client connection ,上面有一些 Mesos 传递方式,有一些 channel 。初始化一个 session ,核心在于 gRPC 去 diy 一个 Manager 节点和建立物理上的连接。
Task

这部分代码是 TaskSpec 的一个描述,并不是真正运行时 Task 的表达方式。因为 Spec 其实相当于一个模板, Task 第一个 field 是 ContainerSpec ,从这里可以看出 Task 实际上是对 container 的包装。下面的 Resource requirements 是需要什么样的资源。第三个是 RestartPolicy , Task restart 的时候都有哪些策略。 Placement 对应 Manager constraint 那一部分,把这个 Task 负载到一个什么类型的 Worker 上面。这是 Task 和 Spec 运行前的描述。

这是 Task 的一个结构,它有一个引用是到 Taskspec 上,上面是一些运行信息,比如 Task 最终在哪一个 Node 的 ID 上, Task 最终属于哪一个 Service ,以及 Task slot 。我在 Google Borg 也见到这个 slot 的概念,它是一个逻辑概念,相当于对资源是一个预留。如果一个 Task 在 slot 上失败了,你会发现 slot 还在,这个 Task 历史也会在那儿, Task 不断的在 slot 上重启、重启、重启,它实际上是对资源的一个 reserve 。

这是前面提到的 Task life circle , Task 有这么多状态,这些状态其实是对一个 Task 的抽象。作为 Dockercontainer ,大家会发现状态没有那么多,无非是 running 和非 running 。但作为一个 Task ,它抽象的状态就非常多,可想而知这些状态都是一个状态机,它们之间可能有各种互相的迁移,情况比较复杂。
Service

这是一个 Service ,很多个 stack 构成 Service 。 Service mode 会分 Replicated Service 和 Global Service , Manager 下发一个 Service 的时候分这两种模式。下面一个字段叫 EndpointSpec ,是 Service 对外服务的时候选择哪一种服务发现的方式,目前有两个选项, DNS 和 VIP 。 DNS 相当于为每一个运行时的 Task 生成一个 DNS SRV 结构; VIP 的表现形式是 Task ,因为 Docker inspect Task 的时候, Task 会有一个自己 Task 的 IP ,然后 Task IP 每次请求都打到这个 Task IP 上,通过 IPVS 负载到后面每个容器上。这是运行时 Service 的概念。

SwarmKit 目前代码较少,是一个上升的社区,值得关注。今天的分享就到这里,谢谢大家!
数人云容器管理面板 Crane
国内首个基于最新 Docker SwarmKit 技术的集群管理工具。它根据 Docker 的原生编排功能,采用轻量化架构,帮助开发者快速搭建 DevOps 环境,体验 Docker 的各种最新功能。
Fork me on GitHub !
目前尚无回复