
这是一个创建于 3276 天前的主题,其中的信息可能已经有所发展或是发生改变。
当然测试可能会让你代码变得没有那么漂亮,举个例子:
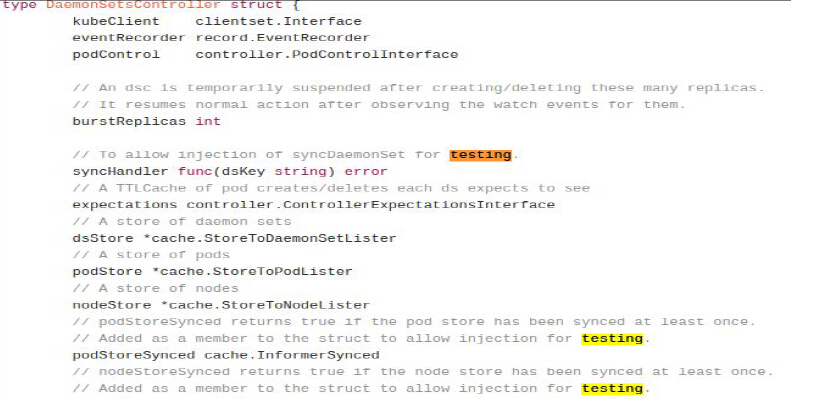
这是知名的 Kubernetes 的代码,就是说它有一个 DaemonSetcontroller ,这 controller 里面注入了三个测试点,比如这个地方注入了一个 handler ,你可以认为所有的注入都是 interface 。比如说你写一个简单的 1+1=2 的程序,假设我们写一个计算器,这个计算器的功能就是求和,那这就很难注入错误。所以你必须要在你正确的代码里面去注入测试逻辑。再比如别人 call 你的这个 add 的 function ,然后你是不是有一个 error ?这个 error 的问题是它可能永远不会返回一个 error ,所以你必须要人肉的注进去,然后看应用程序是不是正确的行为。说完了加法,再说我们做一个除法。除法大家知道可能有处理异常,那上面是不是能正常处理呢?上面没有,上面写着一个比如说 6 ÷ 3 ,然后写了一个 test , coverage 100%,但是一个除零异常,系统就崩掉了,所以这时候就需要去注入错误。大名鼎鼎的 Kubernetes 为了测试各种异常逻辑也采用类似的方式,这个结构体不算长,大概是十几个成员,然后里面就注入了三个点,可以在里面注入错误。
那么在设计 TiDB 的时候,我们当时是怎么考虑 test 这个事情的?首先一个百万级的 test 不可能由人肉来写,也就是说你如果重新定义一个自己的所谓的 SQL 语法,或者一个 query language ,那这个时候你需要构建百万级的 test ,即使全公司去写,写个两年都不够,所以这个事情显然是不靠谱的。但是除非说我的 query language 特别简单,比如像 MongoDB 早期的那种,那我一个“大于多少”的这种,或者 equal 这种条件查询特别简单的,那你确实是不需要构建这种百万级的 test 。但是如果做一个 SQL 的 database 的话,那是需要构建这种非常非常复杂的 test 的。这时候这个 test 又不能全公司的人写个两年,对吧?所以有什么好办法呢? MySQL 兼容的各种系统都是可以用来 test 的,所以我们当时兼容 MySQL 协议,那意味着我们能够取得大量的 MySQL test 。不知道有没有人统计过 MySQL 有多少个 test ,产品级的 test 很吓人的,千万级。然后还有很多 ORM , 支持 MySQL 的各种应用都有自己的测试。大家知道,每个语言都会 build 自己的 ORM ,然后甚至是一个语言的 ORM 都有好几个。比如说对于 MySQL 可能有排第一的、排第二的,那我们可以把这些全拿过来用来测试我们的系统。
但对于有些应用程序而言,这时候就比较坑了。就是一个应用程序你得把它 setup 起来,然后操作这个应用程序,比如 WordPress ,而后再看那个结果。所以这时候我们为了避免刚才人肉去测试,我们做了一个程序来自动化的 Record---Replay 。就是你在首次运行的时候,我们会记录它所有执行的 SQL 语句,那下一次我再需要重新运行这个程序的时候怎么办?我不需要运行这个程序了,我不需要起来了,我只需要把它前面记录的 SQL record 重新回放一遍,就相当于是我模拟了程序的整个行为。所以我们在这部分是这样做的自动化。 那么刚刚说了那么多,实际上做的是什么?实际上做的都是正确路径的测试,那几百万个 test 也都是做的正确的路径测试,但是错误的路径怎么办?很典型的一个例子就是怎么做 Fault injection 。硬件比较简单粗暴的模拟网络故障可以拔网线,比如说测网络的时候可以把这个网线拔掉,但是这个做法是极其低效的,而且它是没法 scale 的,因为这个需要人的参与。
然后还有比如说 CPU ,这个 CPU 的损坏概率其实也挺高的,特别是对于过保了的机器。然后还有磁盘,磁盘大概是三年百分之八点几的损坏率,这是一篇论文里面给出的数据。我记得 Google 好像之前给过一个数据,就是 CPU 、网卡还有磁盘在多少年之内的损坏率大概是什么样的。
还有一个大家不太关注的就是时钟。先前,我们发现系统时钟是有回跳的,然后我们果断在程序里面加个监测模块,一旦系统时钟回跳,我们马上把这个检测出来。当然我们最初监测出这个东西的时候,用户是觉得不可能吧,时钟还会有回跳?我说没关系,先把我们程序开了监测一下,然后过段时间就检测到,系统时钟最近回跳了。所以怎么配 NTP 很重要。然后还有更多的,比如说文件系统,大家有没有考虑过你写磁盘的时候,磁盘出错会怎么办?好,写磁盘的时候没有出错,成功了,然后磁盘一个扇区坏了,读出来的数据是损坏的,怎么办?大家有没有 checksum ?没有 checksum 然后我们直接用了这个数据,然后直接给用户返回了,这个时候可能是很要命的。如果这个数据刚好存的是个元数据,而元数据又指向别的数据,然后你又根据元数据的信息去写入另外一份数据,那就更要命了,可能数据被进一步破坏了。
所以比较好的做法是什么?
- Fault injection
- Hardware
- disk error
- network card
- cpu
- clock
- Software
- file system
- network & protocol
- Simulate everything
模拟一切东西。就是磁盘是模拟的,网络是模拟的,那我们可以监控它,你可以在任何时间、任何的场景下去注入各种错误,你可以注入任何你想要的错误。比如说你写一个磁盘,我就告诉你磁盘满了,我告诉你磁盘坏了,然后我可以让你 hang 住,比如 sleep 五十几秒。我们确实在云上面出现过这种情况,就是我们一次写入,然后被 hang 了为 53 秒,最后才写进去,那肯定是网络磁盘,对吧?这种事情其实是很吓人的,但是肯定没有人会想说我一次磁盘写入然后要耗掉 53 秒,但是当 53 秒出现的时候,整个程序的行为是什么? TiDB 里面用了大量的 Raft ,所以当时出现一个情况就是 53 秒,然后所有的机器就开始选举了,说这肯定是哪儿不对,重新把 leader 都选出来了,这时候卡 53 秒的哥们说“我写完了”,然后整个系统状态就做了一次全新的迁移。这种错误注入的好处是什么?就是知道当出错的时候,你的错误能严重到什么程度,这个事情很重要,就是 predictable ,整个系统要可预测的。如果没有做错误路径的测试,那很简单的一个问题,现在假设走到其中一条错误路径了,整个系统行为是什么?这一点不知道是很吓人的。你不知道是否可能破坏数据;还是业务那边会 block 住;还是业务那边会 retry ?
以前我遇到一个问题很有意思,当时我们在做一个消息系统,有大量连接会连这个,一个单机大概是连八十万左右的连接,就是做消息推送。然后我记得,当时的 swap 分区开了,开了是什么概念?当你有更多连接打进来的时候,然后你内存要爆了对吧?内存爆的话会自动启用 swap 分区,但一旦你启用 swap 分区,那你系统就卡成狗了,外面用户断连之后他就失败了,他得重连,但是重连到你正常程序能响应,可能又需要三十秒,然后那个用户肯定觉得超时了,又切断连接又重连,就造成一个什么状态呢?就是系统永远在重试,永远没有一次成功。那这个行为是不是可以预测?这种错误当时有没有做很好的测试?这都是非常重要的一些教训。
硬件测试以前的办法是这样的(Joke):

假设我一个磁盘坏了,假设我一个机器挂了,还有一个假设它不一定坏了也不一定挂了,比如说它着火了会怎么样?前两个月吧,是瑞士还是哪个地方的一个银行做测试,那哥们也挺逗的,人肉对着服务器这样吹气,来看监控数据那个变化,然后那边马上开始报警。这还只是吹气而已,那如果更复杂的测试,比如说你着火从哪个地方开始烧,先烧到硬盘、或者先烧到网卡,这个结果可能也是不一样的。当然这个成本很高,然后也不是能 scale 的一种方案,同时也很难去复制。
这不仅仅是硬件的监控,也可以认为是做错误的注入。比如说一个集群我现在烧掉一台会怎么样?着火了,很典型的嘛,虽然重要的机房都会有这种防火、防水等各种的策略,但是真的着火的时候怎么办?当然你不能真去烧,这一烧可能就不止坏一台机器了,但我们需要使用 Fault injection 来模拟。
我介绍一下到底什么是 Fault injection 。给一个直观的例子,大家知道所有人都用过 Unix 或者 Linux 的系统,大家都知道,很多人习惯打开这个系统第一行命令就是 ls 来列出目录里面的文件,但是大家有没有想过一个有意思的问题,如果你要测试 ls 命令实现的正确性,怎么测?如果没有源代码,这个系统该怎么测?如果把它当成一黑盒这个系统该怎么测?如果你 ls 的时候磁盘出现错误怎么办?如果读取一个扇区读取失败会怎么办? 这个是一个很好玩的工具,推荐大家去玩一下。就是当你还没有做更深入的测试之前,可以先去理解一下到底什么是 Fault injection ,你就可以体验到它的强大,一会我们用它来找个 MySQL 的 bug 。
libfiu - Fault injection in userspace
It can be used to perform fault injection in the POSIX API without having to modify the application's source code, that can help to test failure handling in an easy and reproducible way.
那这个东西主要是用来 Hook 这些 API 的,它很重要的一点就是它提供了一个 library ,这个 library 也可以嵌到你的程序里面去 hook 那些 API 。就比如说你去读文件的时候,它可以给你返回这个文件不存在,可以给你返回磁盘错误等等。最重要的是,它是可以重来的。
举一个例子,正常来讲我们敲 ls 命令的时候,肯定是能够把当前的目录显示出来。
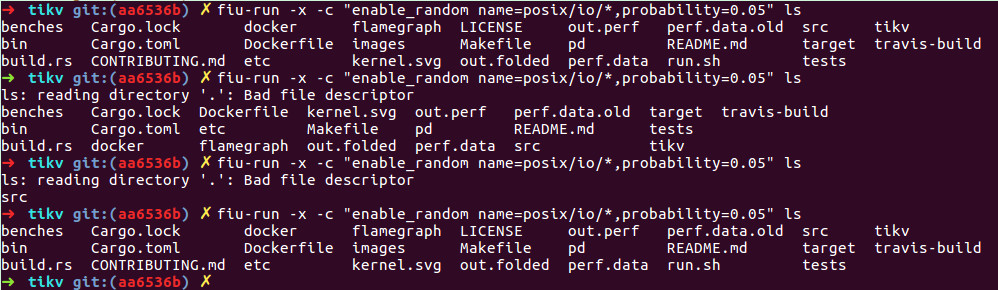
这个程序干的是什么呢?就是 run ,指定一个参数,现在是要有一个 enable_random ,就是后面所有的对于 IO 下面这些 API 的操作,有 5% 的失败率。那第一次是运气比较好,没有遇到失败,所以我们把整个目录列出来了。然后我们重新再跑一次,这时候它告诉我有一次读取失败了,就是它 read 这个 directory 的时候,遇到一个 Bad file descriptor ,这时候可以看到,列出来的文件就比上面的要少了,因为有一条路径让它失败了。接下来,我们进一步再跑,发现刚列出来一个目录,然后下次读取就出错了。然后后面再跑一次的时候,这次运气也比较好,把这整个都列出来了,这个还只是模拟的 5% 的失败率。就是有 5% 的概率你去 read 、去 open 的时候会失败,那么这时候可以看到 ls 命令的行为还是很 stable 的,就是没有什么常见的 segment fault 这些。
大家可能会说这个还不太好玩,也就是找找 ls 命令是否有 bug 嘛,那我们复现 MySQL bug 玩一下。
Bug #76020
InnoDB does not report filename in I/O error message for reads
fiu-run -x -c "enable_random name=posix/io/*,probability=0.05" bin/mysqld --basedir=/data/ushastry/server/mysql-5.6.24 --datadir=/data/ushastry/server/mysql-5.6.24/76020 --core-file --socket=/tmp/mysql_ushastry.sock --port=15000
2015-05-20 19:12:07 31030 [ERROR] InnoDB: Error in system call pread(). The operating system error number is 5.
2015-05-20 19:12:07 7f7986efc720 InnoDB: Operating system error number 5 in a file operation.
InnoDB: Error number 5 means 'Input/output error'.
2015-05-20 19:12:07 31030 [ERROR] InnoDB: File (unknown):
'read' returned OS error 105. Cannot continue operation
这是用 libfiu 找到的 MySQL 的一个 bug ,这个 bug 是这样的, bug 编号是 76020 ,是说 InnoDB 在出错的时候没有报文件名,那用户给你报了错,你这时候就傻了对吧?这个到底是什么地方出错了呢?然后这个地方它怎么出来的?你可以看到它还是用我们刚才提到的 fiu-run ,然后来模拟,模拟的失败概率还是这么多,可以看到,我们的参数一个没变,这时把 MySQL 启动,然后跑一下,出现了,可以看到 InnoDB 在报的时候确实没有报 filename , File : 'read' returned OS error ,然后这边是 auto error ,你不知道是哪一个文件名。
换一个思路来看,假设没有这个东西,你复现这个 bug 的成本是什么?大家可以想想,如果没有这个东西,这个 bug 应该怎么复现,怎么让 MySQL 读取的东西出错?正常路径下你让它读取出错太困难了,可能好多年没出现过。这时我们进一步再放大一下,这个在 5.7 里面还有,也是在 MySQL 里面很可能有十几年大家都没怎么遇到过的,但这种 bug 在这个工具的辅助下,马上就能出来。所以 Fault injection 它带来了很重要的一个好处就是让一个东西可以变得更加容易重现。这个还是模拟的 5% 的概率。这个例子是我昨天晚上做的,就是我要给大家一个直观的理解,但是分布式系统里面错误注入比这个要复杂。而且如果你遇到一个错误十年都没出现,你是不是太孤独了? 这个电影大家可能还有印象,威尔史密斯主演的,全世界就一个人活着,唯一的伙伴是一条狗。

实际上不是的,比我们痛苦的人大把的存在着。
举 Netflix 的一个例子,下图是 Netflix 的系统。
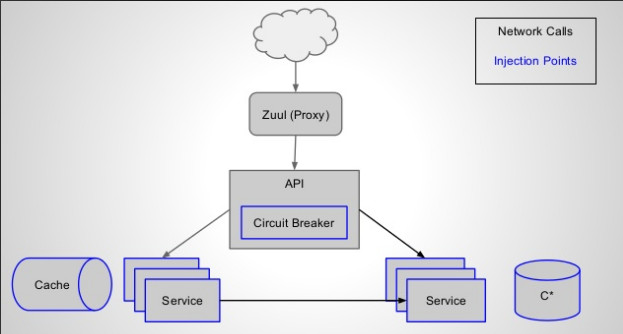
他们在 2014 年 10 月份的时候写了一篇博客,叫《 Failure Injection Testing 》,是讲他们整个系统怎么做错误注入,然后他们的这个说法是 Internet Scale ,就是整个多数据中心互联网的这个级别。大家可能记得 Spanner 刚出来的时候他们叫做 Global Scale ,然后这地方可以看到,蓝色是注射点,黑色的是网络调用,就是所有这些请求在这些情况下面,所有这些蓝色的框框都有可能出错。大家可以想一想,在 Microservice 系统上,一个业务调用可能涉及到几十个系统的调用,如果其中一个失败了会怎么样?如果是第一次第一个失败,第二次第二个失败,第三次第三个失败是怎么样的?有没有系统做过这样的测试?有没有系统在自己的程序里面去很好的验证过是不是每一个可以预期的错误都是可预测的,这个变得非常的重要。这里以 cache 为例,就说每一次访问 Cassandra 的时候可能出错,那么也就给了我们一个错误的注入点。
然后我们谈谈 OpenStack
OpenStack fault-injection library:
大名鼎鼎的 OpenStack 其实也有一个 Failure Injection Library ,然后我把这个例子也贴到这里,大家有兴趣可以看一下这个 OpenStack 的 Failure Injection 。这以前大家可能不太关注,其实大家在这一点上都很痛苦, OpenStack 现在还有一堆人在骂,说稳定性太差了,其实他们已经很努力了。但是整个系统确实是做的异乎寻常的复杂,因为组件太多。如果你出错的点特别多,那可能会带来另外一个问题,就是出错的点之间还能组合,就是先 A 出错,再 B 出错,或者 AB 都出错,这也就几种情况,还好。那你要是有十万个错误的点,这个组合怎么弄?当然现在还有新的论文在研究这个, 2015 年的时候好像有一篇论文,讲的就是会探测你的程序的路径,然后在对应的路径下面去注入错误。
再来说 Jepsen
Jepsen: Distributed Systems Safety Analysis

大家所有听过的知名的开源分布式系统基本上都被它找出来过 bug 。但是在这之前大家都觉得自己还是很 OK 的,我们的系统还是比较稳定的,所以当新的这个工具或者新的方法出现的时候,就比如说我刚才提到的那篇能够线性 Scale 的去查错的那篇论文,那个到时候查错力就很惊人了,因为它能够自动帮你探测。另外我介绍一个工具 Namazu ,后面讲,它也很强大。这里先说 Jepsen, 这货算是重型武器了,无论是 ZooKeeper 、 MongoDB 以及 Redis 等等,所有这些全部都被找出了 bug ,现在用的所有数据库都是它找出的 bug ,最大的问题是小众语言 closure 编写的,扩展起来有点麻烦。我先说说 Jepsen 的基本原理,一个典型使用 Jepsen 的测试通过会在一个 control node 上面运行相关的 clojure 程序, control node 会使用 ssh 登陆到相关的系统 node ( jepsen 叫做 db node )进行一些测试操作。
当我们的分布式系统启动起来之后, control node 会启动很多进程,每一个进程都能使用特定的 client 访问到我们的分布式系统。一个 generator 为每一个进程生成一系列的操作,比如 get/set/cas ,让其执行。每一个操作都会被记录到 history 里面。在执行操作的同时,另一个 nemesis 进程会尝试去破坏这个分布式系统,譬如使用 iptable 断开网络连接等,当所有操作执行完毕之后, jepsen 会使用一个 checker 来分析验证系统的行为是否符合预期。 PingCAP 的首席架构师唐刘写过两篇文章介绍我们实际怎么用 Jepsen 来测试 TiDB ,大家可以搜索一下,我这里就不详细展开了。
- FoundationDB
- It is difficult to be deterministic
- Random
- Disk Size
- File Length
- Time
- Multithread
FoundationDB 这就是前辈了, 2015 年被 Apple 收购了。他们为了解决错误注入的问题,或者说怎么去让它重现的这个问题,做了很多事情,很重要的一个事情就是 deterministic 。如果我给你一样的输入,跑几遍,是不是能得到一样的输出?这个听起来好像很科学、很自然,但是实际上我们绝大多数程序都是做不到的,比如说你们有判断程序里面有随机数吗?有多线程吗?有判断磁盘空间吗?有判断时间吗?你再一次判断的时候还是一样的吗?你再跑一次,同样的输入,但行为已经不一样了,比如你生了一个随机数,比如你判断磁盘空间,这次判断和下次判断可能是不一样的。
所以他们为了做到“我给你一样的输入,一定能得到一样的输出”,花了大概两年的时间做了一个库。这个库有以下特性:它是个单线程的,然后是个伪并发的。为什么?因为如果用多线程你怎么让它这个相同的输入变成相同的输出,谁先拿到锁呢?这里面的问题很多,所以他们选择使用单线程,但是单线程本身有单线程的问题。而且比如你用 Go 语言,那你单线程它也是个并发的。然后它的语言规范就告诉我们说,如果一个 select 作用在两个 channel 上,两个 channel 都 ready 的时候,它会随机的一个,就是在语言定义的规范上面,就已经不可能让你得到一个 deterministic 了。但还好 FoundationDB 是用 C++ 写的。
- FoundationDB
- Single-threaded pseudo-concurrency
- Simulated the implementation of all the external communication
- Determinism
- Disasters happen more frequently here than in the real world.
另外 FoundationDB 模拟了所有的网络,就是两个之间认为通过网络通讯,对吧?实际上是通过它自己模拟的一套东西在通讯。它里面有一个很重要的观点就是说,如果磁盘损坏,出现的概率是三年百分之八的话,那么在用户那出现的概率是三年百分之八。但是在用户那一旦出现了,那证明就很严重了,所以他们对待这个问题的办法是什么?就是我通过自己的模拟系统让它每时每刻都在产生。它们大概是每两分钟产生一次磁盘损坏,也就是说它比现实中的概率要高几十万倍,所以它就觉得它调的技术 more frequently ,就是我这种错误出现的更加频繁,那网卡损坏的概率是多少?这都是极低的,但是你可以用这个系统让它每分每秒都产生,这样一来你就让你的系统遇到这种错误的概率是比现实中要大非常非常多。那你重现,比如说现实中跑三年能重现一次,你可能跑三十秒就能重现一次。
但对于一个 bug 来说最可怕的是什么?就是它不能重现。发现一个 bug ,后来说我 fix 了,然后不能重现了,那你到底 fix 了没有?不知道,这个事情就变得非常的恐怖。所以通过 deterministic 肯定能保证重现,我只要把我的输入重放一次,我把它录下来,每一次我把它录下来一次,然后只要是曾经出现过,我重放,一定能出现。当然这个代价太大了,所以现在学术界走的是另外一条路,不是完全 deterministic ,但是我只需要它 reasonable 。比如说我在三十分钟内能把它重现也是不错的,我并不需要在三秒内把它重现。所以,每前一步要付出相应的成本代价。
 |
1
PingCAP OP 本话题系列文章整理自 PingCAP NewSQL Meetup 第 26 期刘奇分享的《深度探索分布式系统测试》议题现场实录。文章较长,为方便大家阅读,会分为上中下三篇,本文为中篇。
|
 |
2
wodesuck 2016-12-20 21:52:31 +08:00
看过了,但还是顶一下。
|