
这是一个创建于 2709 天前的主题,其中的信息可能已经有所发展或是发生改变。
公司需求 所以开始写爬虫
第一次写 直接 curl 请求 web 端 折腾了一下午算是搞定了 可是速度很慢 而且频繁被验证码限制
第二天搞了台拨号的机器 每次验证码就直接断了宽带重新拨号(动态 ip ) 但是速度还是很慢
第三天刷了一下关于爬虫的乱七八糟的知识 开始重写
重写是利用 curl_multi 进行并发请求 这次是爬 H5 端 H5 端验证码的频率比 web 端要低很多
但是新的问题出现了 放到之前拨号的机器上基本上一个页面就弹一次验证码 换 IP 也一样
本地跑就不会这样 而且重拨后 curl_multi 就会报链接超时的错误 于是就放在本地跑
但是验证码的问题还是没有解决 于是就开始摸索网站验证码的规律
几天下来还是没有太大的发现 不管是降低访问频率 还是更改爬取顺序 基本上都没什么太大变化
于是考虑从过验证码下手 验证码是纯底色 没有干扰 只是字体会变形旋转
又折腾了下 Tesseract-OCR 识别率太低 达不到想要的效果
想问几个问题 :
- 电商网站一般都是什么反爬虫策略? 被验证码限制最多的时候就是一个循环完成后 下一个循环第一个页面被限制,最近几天在其他时候被验证码限制的情况发生频率高了一些 有用 sleep()限制频率依然没什么用
- 爬虫 dalao 们都是怎么对抗验证码的 除了代理 IP,以及对验证码识别有没有什么效率比较高的办法 看 Tesseract-OCR 是有深度学习?的特性 但是没搞太明白
- 拨号的那台机器用爬 H5 端的爬虫为什么会这么频繁被限制本地却不会这样 每次重拨大概率 IP 都会换 应该不是黑名单的问题吧?本地基本都是输入验证码接着重新开一下爬虫就好了
- 如果用 php-thread 真正独立线程编写爬虫 重拨 IP 会不会出现超时的 error
- Tesseract-OCR 配置 tessedit_char_whitelist 后会报错 read_params_file: Can't open tessedit_char_whitelist; 白名单只是添加了 a-z
作为新手可能会问出比较蠢的问题 水平有限 希望见谅 = =
有需要提供更多详细信息的我会补充 爬虫工具是用的 V2dalao querylist 致谢
第 1 条附言 · 2017-07-21 15:00:52 +08:00
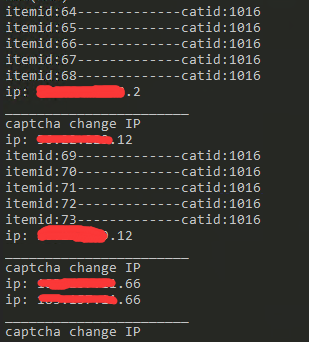
这是拨号的那台机器 换一次IP插入几条就会立刻被验证码限制
下划线是分割 上面的是当前IP 下面的是重拨后的IP
大部分情况下换了IP第一次访问就被验证码限制
cookie是禁用的 user-agent是随机的移动设备user-agent
用工作的机器跑大概能跑上万条数据才会被验证码限制
 |
1
Le4fun 2017-07-21 09:57:05 +08:00
同新手占楼学习
|
 |
2
mansur 2017-07-21 10:12:28 +08:00 代理可购买,如果采集对象是 https 的,建议自建代理池。简单验证码可接打码平台,复杂的只能靠代理池绕过了。
|
 |
4
hxndg 2017-07-21 10:53:02 +08:00 我只知道一种对抗爬虫的技术,正常情况下用户看不到隐藏的链接,谁爬到了就禁止谁访问。
|
 |
5
soulmine 2017-07-21 10:55:16 +08:00 @2ME 验证码还是推荐人工 各种算法都有上限值 而且程序复杂度会翻几个数量级 还有那准确率就看天了 www 如果是登陆时候需要验证码的话 可以试试带带 cookies
|
 |
7
2ME OP @soulmine 验证码是爬取一段时间的限制措施 验证码 纯色背景 没有干扰噪点 只是验证码形状会扭曲一些 4 位数字+字母 感觉比平时的站验证码都要简单一些
|
 |
9
wangxiaoer 2017-07-21 11:00:23 +08:00
@hxndg 这种对定向抓取没啥用吧
|
|
10
soulmine 2017-07-21 11:07:23 +08:00
@wangxiaoer 而且这样还有个问题 你怎么区分正常情况和爬虫情况 靠 header 头么 www
|
 |
11
nullen 2017-07-21 11:08:52 +08:00
简单一些的验证码,MINST 手写数字识别就可以过掉了。
|
|
12
soulmine 2017-07-21 11:10:01 +08:00 @2ME 这个好办啊 你限个速不就行了 肯定是有阈值的 你别去摧残她网站 自然不会给你验证码了 www 追求速度就跑多进程好了 只不过你得搞代理 ip 了
|
|
13
2ME OP @soulmine 我最近一个星期一直在找临界点 比较有趣的是不管我速度放的有多慢 基本上数据库 6000-12000 通常 1w 条数据就出验证码了 速度最慢的时候接近单线程单请求 现在是多并发请求
|
 |
15
KgM4gLtF0shViDH3 2017-07-21 11:27:38 +08:00
为啥不上付费平台,又不贵,验证码自己搞很累的。要是我做反爬虫就直接针对那些访问多的爬虫返回没用的假数据。
|
|
16
2ME OP 话说被 V 站禁言系统误伤 半小时不能发言 @soulmine 如果只是看个数的话我也不会说有趣了= = 我帖子内容有讲我有另一台可以拨号上网的机器实现代理功能 每次重拨都会更换 ip 一样开始单线程就是用那台机器跑 可是我把新写好并发请求的爬虫放到那台机器去跑几乎每隔一两个页面就会被弹验证码 百思不得其解
|
 |
17
niuoh 2017-07-21 12:07:12 +08:00
可以上爬虫代理 推荐个用着不错的 ip 池 ip-chi#net
|
 |
18
misaka19000 2017-07-21 12:29:41 +08:00 via Android 验证码试试 KNN 算法
|
 |
19
aaronzjw 2017-07-21 12:44:04 +08:00 via Android 验证码用 cnn 模型
|
 |
20
MrMario 2017-07-21 12:59:55 +08:00 via iPhone 验证码用 svm 算法
|
 |
21
golmic 2017-07-21 13:04:48 +08:00 via Android
留个微信号可以跟楼主交流一下。
|
|
22
2ME OP 看了看各位 dalao 推荐的算法模型啥的 感觉对我来说超纲了 orz
|
 |
23
lommo 2017-07-21 13:05:29 +08:00
关键信息都是图片的很伤的
|
 |
24
Wetoria 2017-07-21 14:10:36 +08:00 via iPhone
我和我同学爬过某电商平台,数据是动态出来的,怎么破?🤷🏻♂️
我同学爬某东,前几页数据正常,爬到后面开始为第一页的重复数据。🤷🏻♂️ 正常情况与爬虫,主要就是访问量的差别了吧?原来搞爬虫看到的一句话“爬虫与反爬的战争中,爬虫终将获胜。”你的网站只要能被正常访问,就一定能被爬。 反爬策略封 ip,加验证码,是不是还有个 ajax 异步加载数据??我记得另外爬了一个网站,访问结果就是一条链接🌚 |
 |
25
qsmy 2017-07-21 14:20:15 +08:00 如果验证码简单,只是轻微粘连和扭曲变形,可以尝试 Tesseract-OCR 的机器学习,学习个几百次就能明显提高识别率。
|
|
26
2ME OP @qsmy 恩 现在正在找机器学习的办法 还没太搞懂 不过 Tesseract-OCR 配置 tessedit_char_whitelist 总是用不了 感觉白名单生效的话会提高很多 不会匹配一堆奇奇怪怪的字符
|
 |
27
qqpkat2 2017-07-21 14:37:37 +08:00
毫无压力,浏览器模拟一切爬虫~
|
 |
28
rswl 2017-07-21 15:03:01 +08:00
程序员之间的较量
|
 |
29
DCjanus 2017-07-21 17:33:23 +08:00 访问频率可能是根据访问时长来限制阈值的:正常人访问时间一般比较短,爬虫几乎必然是长时间、不间断访问。
也就是说你连续请求时间越长,针对你的访问频率阈值就会越低。 爬虫如果不限制频率,很短时间内就会触发短期阈值;即使限制了频率,长时间访问也会碰到长期阈值。 这种基本上无解,只能靠大量代理来解决。 当然,如果你能知道他们的具体函数的话那就美滋滋了,比如知道多久不请求就会重置阈值以及阈值和访问时长的联系。 另外部分网站出现过的情况,页面里一堆只有爬虫才能看到的数据,给你的数据投毒 2333 还会用 csv 画出来的价格标签,真人看起来没什么区别,爬虫爬回来就是一堆 csv,你还得跟验证码识别一样去识别价格标签。 另外有的网站随机请求间隔比固定间隔有更高的效率。 |
|
31
2ME OP 感觉收藏的要比回复的多得多..
|
|
32
2ME OP @qsmy 折腾了一天 弄了下 Tesseract-OCR 识别验证码 500 次学习 识别成功率一般 但是还算能用 已经放定时任务了 想问下还有没有其他提高识别率的办法 或者其他开源的图像识别~
|
|
33
qsmy 2017-07-25 11:24:59 +08:00 via iPad @2ME 你不会是直接拿验证码识别的吧?需要先对验证码图片进行处理,比如彩色转黑白、加粗、去噪等。把识别难度降低再去学习。
|
|
34
2ME OP @qsmy - - 确实没处理 直接拿去学习了 暂时先用着 早上正在看图片怎么处理好一些 图片没噪点 只是扭曲和字体比较烦人 命令行识别度比训练的 GUI 降低很多不知道为什么 GUI 基本永远都是 4 个字符的验证 命令行识别出来的经常出现更多的字符..
|