
1.HTTP 协议详解与抓包工具使用
爬虫开发中的一个重要步骤是请求行为分析,请求行为分析的实质就是 Http/Https 请求与应答分析,了解和掌握 http/https 协议的基本概念对于我们开发爬虫很有必要,所有我们先来了解下 http/https 协议。
1: http/https 协议:
1.http 协议基于 TCP/IP 的超文本传输协议,简单理解下,客户端和服务端传输的数据按照设定好的规则通过 TCP 进行传输,这个规则就是我们所说的 http 协议,传输的数据是没有经过加密的明文数据;发送端按照规则组装数据,接收端按照规则解析数据,这样就能得到正确信息;
2.http 协议是一个无连接无状态的协议,当客户端发起一个请求收并且收到应答后,这个连接就关闭了,所以服务端不会记录客户端的状态;然后我们会有一个问题,当我们登录一个网站的时候,他是如何记录我们状态?这个问题在后面我在详细讲解。
3.https 协议: http 协议因为是明文传输,所有存在安全问题,于是业界大牛就基于 Http 协议与 SLL 协议定义了 https 协议;将传输的数据进行加密处理,这样保证数据安全性。这里我们关注点不在数据如何加解密,而是分析请求行为,所以这部分不做过多的描述;
2:Http 请求过程分析:
到这里我们对 Http/Https 协议基本了解,下面通过一张图描述下浏览器访问一个网站时候所发生事情,并找到我们关注点:
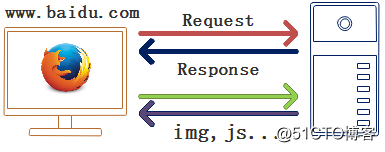
图中的 Request 是浏览器发起请求信息,Response 是服务器回应的应答信息;当浏览器收到应答对页面解析后,还要再次请求其它资源,比如图片,JS 等;
我们关注的就是 Request 请求信息及 Response 应答信息;
3:Request 请求分析:
下面我们就来看一组报文(请求地址:https://www.httpbin.org/get ),然后去介绍 http 协议中我们关注的知识点;
GET /get HTTP/1.1
Host: www.httpbin.org
Connection: keep-alive
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,/;q=0.8
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
我们所关注的:请求方法,请求地址,请求头信息;
Http 协议支持 Get/Post/Put/Delete 等方法,在这里我们主要使用 Get 与 Post 方法;
Get 方法:主要请求资源,比如浏览页面,图片等行为;
Post 方法:提交表单,文件等操作,例如:注册登录等行为;
请求头信息我们主要关注下面截个字段:
1.User-Agent:请求客户端信息,例如浏览器类型 /版本,系统类型 /版本等信息;
2.Accept-Encoding:客户端支持编码格式,服务器可以根据客户端支持的格式对数据进行压缩传输;
3.Cookie:记录客户端状态字段,这个字段意思在进行登录那节在详解讲解;
其它字段,我们暂时可以先去网上查找资料了解下;
从这个请求头信息中我们可以得到信息:我们在 PC 端使用 chrome 浏览器使用 get 方法请求 https://www.httpbin.org/get 资源。
4:Response 应答分析:
当我们成功发起一个请求之后,就会收到 Response 应答,我们来看一下应答的报文:
HTTP/1.1 200 OK
Connection: keep-alive
Server: gunicorn/19.9.0
Date: Thu, 09 Aug 2018 05:27:48 GMT
Content-Type: application/json
Content-Length: 570
Access-Control-Allow-Origin: *
Access-Control-Allow-Credentials: true
Via: 1.1 vegur
我们来简单分析下报文头信息:
1.协议版本:HTTP/1.1 ;
2.应答状态码:200,代表请求成功;
3.Content-Type:应答内容的数据类型,这里是 Json 形式;
4.Content-Length:应答内容数据长度;
这里我们要关注应答状态码,如果状态码不是 200 或者 20x,可能请求就失败;
不同状态码代表不同失败类型,我们简单总结下:
| 消息类型 | 状态码 | 说明 |
|---|---|---|
| 消息 | 1xx | 请求被服务器接收,需要继续处理,例如:101,继续请求 |
| 成功 | 2xx | 请求被服务器正常接收处理,例如:200 |
| 重定向 | 3xx | 请求被接受,但是需要再次请求,例如:302,请求资源不存在,请求新的 URl |
| 请求错误 | 4xx | 例如:403:禁止访问,404:资源不存在 |
| 服务器错误 | 5xx | 服务器处理请求出错,例如:500:服务器运行程序出错 |
以上 http 协议这部分内容就是我们做爬虫经常使用概念,实际工作中,如果有其它不确认的,我们可以借助网上资料去查询相关内容就可以。
5:抓包工具使用:
抓包工具做爬虫开发必不可少的,常用的工具包括浏览器(例如 chrome ),Wireshark, Fidder 等软件,linux 下的 tcpdump 命令,这里我们只是讲解使用 chrome 浏览器对请求行为与页面信息进行分析;
chrome 浏览器抓包使用:
1.打开浏览器,按‘ F12 ’或者右击选择检查,出来下面菜单项,选择‘ Netwrok ’,具体如下图:
2.进行下面操作:
1 )选中 Network,然后地址栏输入 URL,回车
2 )点击右侧 get,可以看到左侧的内容,
3 )点击 headers,查看请求方法,URL,应答状态码;
4 )点击 Response Headers,查看应答头信息;
5 )点击 Request Headers,查看请求头信息;
6 )点击 Response 可以查看服务器应答内容( html/Json );
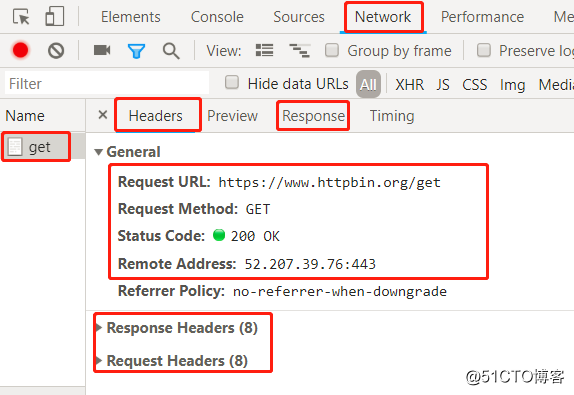
通过这种方式我们就能获取请求过程信息。
在实际场景中,当我们使用浏览器请求一个页面后,页面被浏览器处理,可能会发起更多个请求,而我们想要的信息可能在这后面请求中,所有我们要逐个分析这些请求才能找到我们想要的 URl,这些内容在后面实际案例中我们会详细讲解;6:数据提取中元素定位:
当我们把数据请求完成后,就应该根据需求对数据进行提取,我们收到数据可能为下面两种格式:
1.Json 格式:使用 Json 模块处理,提取相关信息;
2.html 格式:使用 BS4/LXML 模块处理,提取页面中信息;
先来思考下如何在 html 中提取数据?举个例子,提取百度主页中 Logo 图片;
我们可以借助 chrome 浏览器来进行分析,具体步骤如下:
1.打开百度主页:https://www.baidu.com/ ;
2.鼠标放到 logo 图片区域,右击选中菜单中的检查;
3.找到图片的对应的节点与地址,如下图所示:
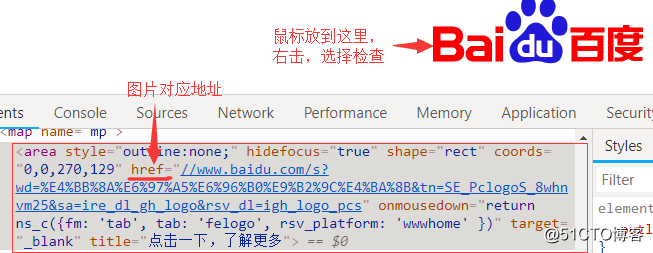
到这里我们就找对应地址,如果我们要编写一个爬虫去抓取这涨图片,具体过程如下:
1.请求百度主页,获取页面信息;
2.使用相关模块提取图片地址;
3.请求图片,并将数据保存到本地文件;
以上的每一步都要使用 Python 相关模块去完成对应工作。
我们来总结下本章节我们必须掌握的内容:
- http 相关知识点:Get/Post 方法,请求与应答头信息重要字段与状态码;
- 使用浏览器分析请求行为;
- 使用浏览器定位元素;
更多免费教程,尽在每日答答官网: https://1024dada.com/?channel=v2ex。