推荐学习书目
› Learn Python the Hard Way
Python Sites
› PyPI - Python Package Index
› http://diveintopython.org/toc/index.html
› Pocoo
值得关注的项目
› PyPy
› Celery
› Jinja2
› Read the Docs
› gevent
› pyenv
› virtualenv
› Stackless Python
› Beautiful Soup
› 结巴中文分词
› Green Unicorn
› Sentry
› Shovel
› Pyflakes
› pytest
Python 编程
› pep8 Checker
Styles
› PEP 8
› Google Python Style Guide
› Code Style from The Hitchhiker's Guide

这是一个创建于 1704 天前的主题,其中的信息可能已经有所发展或是发生改变。
虎嗅获取更多文章的 api 里面找不到和页数相关的参数,我试了提交 cookie 等,都只能获得第一页的数据,求大神指点
第 1 条附言 · 2020-04-28 22:19:58 +08:00
补充一下:
- 爬的网址:https://www.huxiu.com/channel/10.html
- 接口没有和页数有关的参数
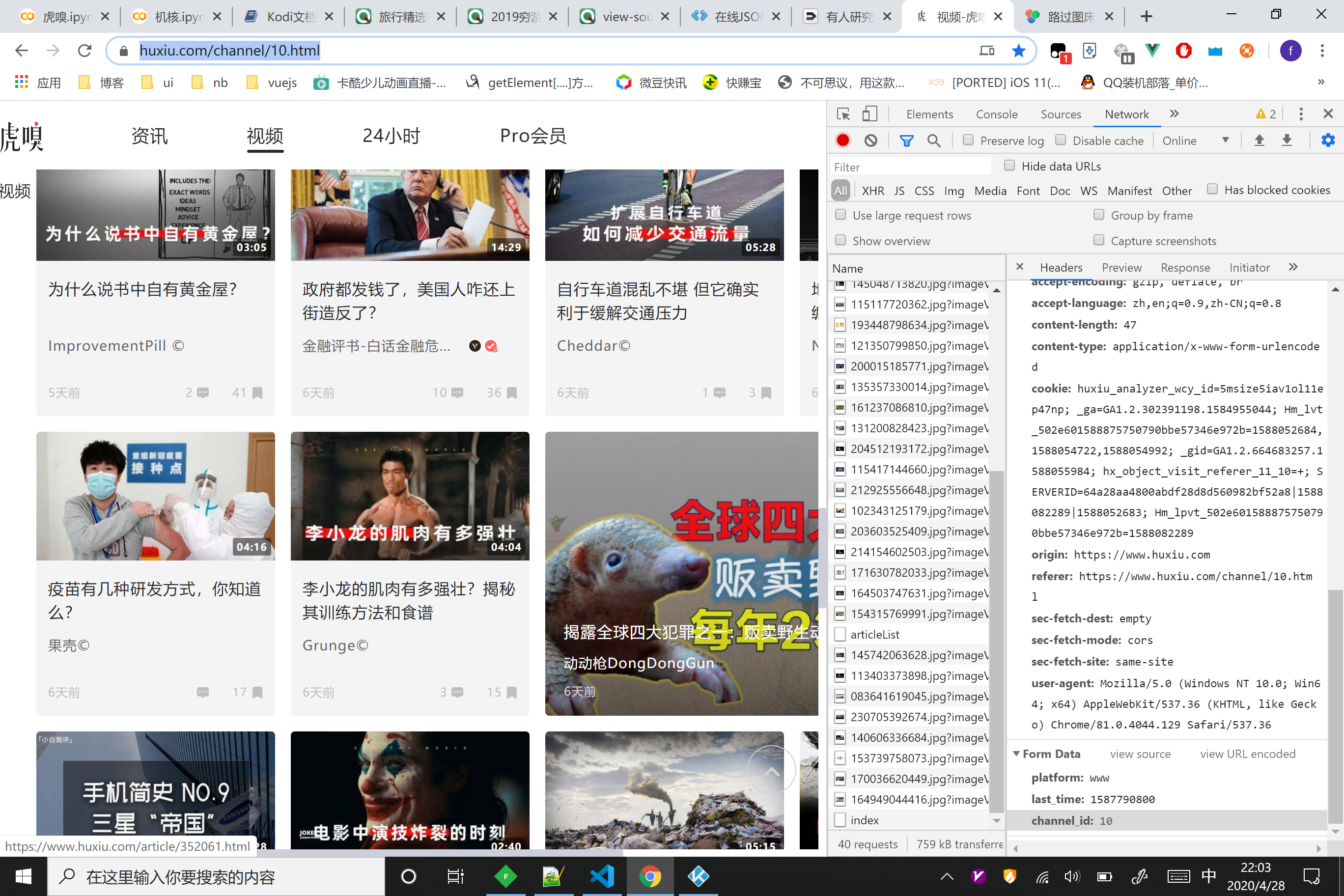
- 这是我第一次碰到这种情况,不知道虎嗅用了什么黑科技,求大神指点一二 QAQ
 |
1
useben 2020-04-28 19:54:52 +08:00
难怪了...
|
 |
2
Enying 2020-04-28 20:04:11 +08:00 via Android
难怪了...
|
 |
3
naomhan 2020-04-28 20:21:13 +08:00
 不是有吗 不是有吗 |
 |
4
delectate 2020-04-28 20:26:49 +08:00
POST https://article-api.huxiu.com/web/article/articleList
DATA platform=www&recommend_time=1588037640&pagesize=22 |
 |
5
zhengfan2016 OP @naomhan 多谢大佬,不过我试了加 pagesize 还是不行 QAQ,只返回第一页的数据
 |
|
6
zhengfan2016 OP @delectate 感谢大佬,不过我试了还是不行
|
 |
7
just1 2020-04-28 22:25:21 +08:00 字段里面有一个 lasttime,就是之前加载过的最老的一个 time
|
|
8
delectate 2020-04-29 06:46:19 +08:00 import time
import requests data = "platform=www&last_time=1587024558&channel_id=10" headers = {"host": "article-api.huxiu.com", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0", "Accept": "application/json, text/plain, */*", "Accept-Language": "en-US,en;q=0.5", "Accept-Encoding": "gzip, deflate, br", "Content-Type": "application/x-www-form-urlencoded", "Referer": "https://www.huxiu.com/channel/10.html", "Content-Length": "47", "Origin": "https://www.huxiu.com", "Cookie": "填入你自己的 cookie", "DNT": "1", "Connnection": "keep-alive"} print(requests.post("https://article-api.huxiu.com/web/channel/articleList", headers=headers, data=data).text) 返回数据: {"success":true,"data":{"name":"\u89c6\u9891","datalist":[{"object_type":1,"article_type":1,"is_original":"0","aid":"350840","title":"\u4e2d\u56fd\u65b0\u57fa\u5efa\u7684\u6cd5\u95e8\uff1a\u5317\u6597\u7fb2\u548c","pic_path":"https:\/\/img.huxiucdn.com\/article\/cover\/202004\/16\/155926474077.jpg?imageView2\/1\/w\/400\/h\/225\/|imageMogr2\/strip\/interlace\/1\/quality\/85\/format\/jpg","is_audio":"0","dateline":"1587024180","formatDate":"2020-04-16","share_url":"https:\/\/m.huxiu.com\/article\/350840.html","origin_pic_path":"https:\/\/img.huxiucdn.com\/article\/cover\/202004\/16\/155926474077.jpg","is_free":"0","is_vip_column_article":false,"summary":"\u7ee7\u4e92\u8054\u7f51\u6539\u53d8\u4e16\u754c\u4e4b\u540e\uff0c\u4f4d\u7f6e\u7f51\u5c06\u4f1a\u6539\u53d8\u6574\u4e2a\u4e2d\u56fd\uff1f","is_hot":false,"count_info":{"aid":"350840","catid":"10","viewnum":84217,"commentnum":2 |
 |
9
ClericPy 2020-04-29 09:34:43 +08:00
这年头学爬虫也要学后端的
这个接口看起来就是处理 offset 过大导致检索效率变低的问题, 常见套路一个是通过只查 id 的嵌套子查询来过滤; 另一个就是不使用 offset, 对连续文档列表的情况借助 last id 的方式. 后者复杂度更低一点 |