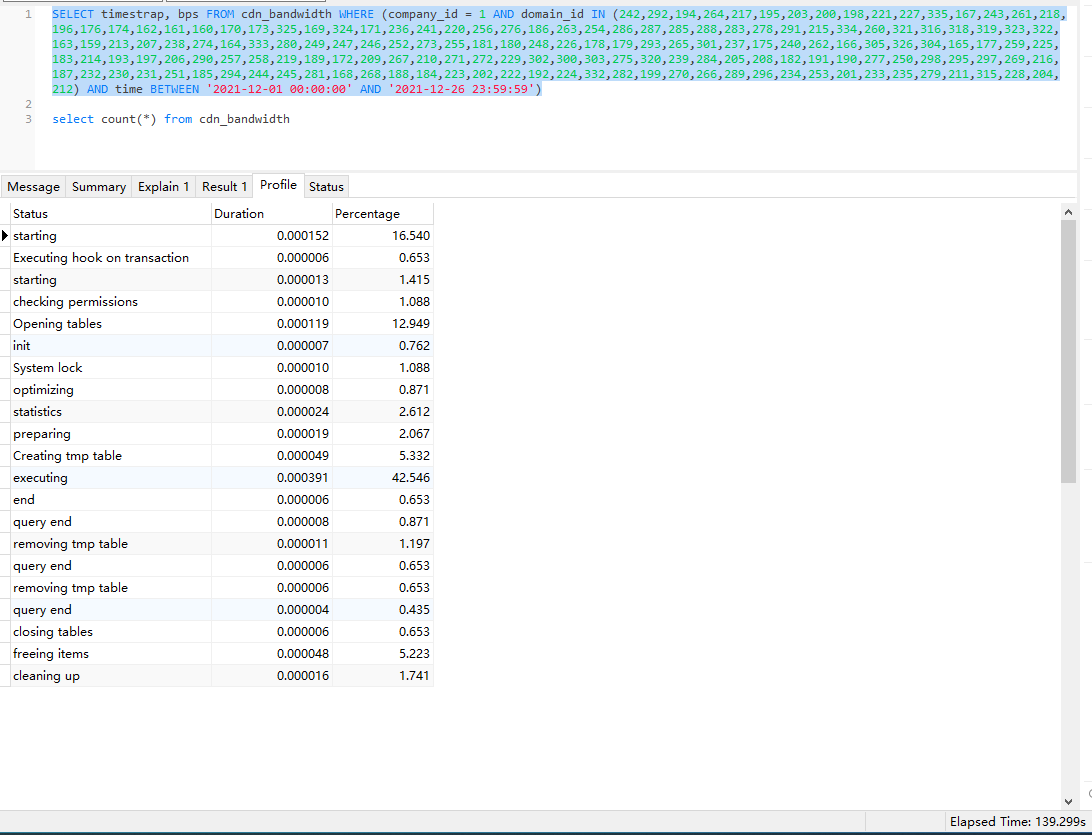
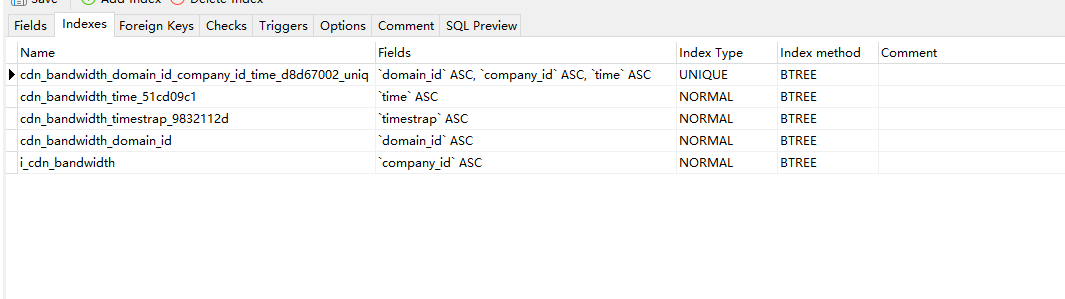
sql 执行语句 SELECT timestrap, bps FROM cdn_bandwidth WHERE (company_id = 1 AND domain_id IN (242,292,194,264,217,195,203,200,198,221,227,335,167,243,261,218,196,176,174,162,161,160,170,173,325,169,324,171,236,241,220,256,276,186,263,254,286,287,285,288,283,278,291,215,334,260,321,316,318,319,323,322,163,159,213,207,238,274,164,333,280,249,247,246,252,273,255,181,180,248,226,178,179,293,265,301,237,175,240,262,166,305,326,304,165,177,259,225,183,214,193,197,206,290,257,258,219,189,172,209,267,210,271,272,229,302,300,303,275,320,239,284,205,208,182,191,190,277,250,298,295,297,269,216,187,232,230,231,251,185,294,244,245,281,168,268,188,184,223,202,222,192,224,332,282,199,270,266,289,296,234,253,201,233,235,279,211,315,228,204,212) AND time BETWEEN '2021-12-01 00:00:00' AND '2021-12-26 23:59:59')
查询出 1038259 条数据,共花费时间 125 秒。太长时间了。有没有办法能优化下。