
这是一个创建于 1905 天前的主题,其中的信息可能已经有所发展或是发生改变。
RT 高频爬取公开数据违法不?比如商品价格,股票价格等等
第 1 条附言 · 2019-09-25 13:10:58 +08:00
其实我就想获取下这个数据:
robots.txt
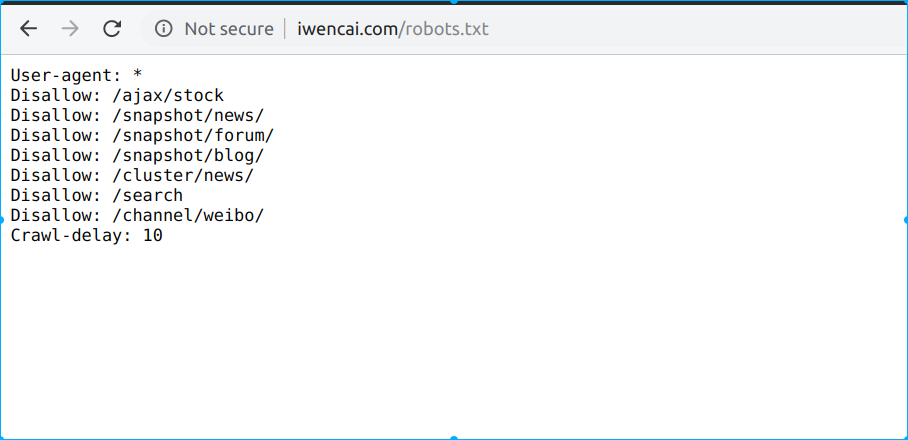
这个怎么讲?可不可以爬取

robots.txt

这个怎么讲?可不可以爬取
 |
1
GeruzoniAnsasu 2019-09-25 11:06:26 +08:00 真正“公开” 的数据 一般会有发布或推送渠道。否则很可能不能算“公开”
|
 |
2
silencefent 2019-09-25 11:08:42 +08:00 看用户协议和 robots
|
 |
3
oma1989 OP @silencefent 好的,谢谢
|
 |
4
murmur 2019-09-25 11:12:55 +08:00
不想让你爬会有反扒和下毒的
|
 |
5
swulling 2019-09-25 11:13:30 +08:00
没有在 robots.txt 允许的,一律为非法爬取,只是算不算你账的问题
|
|
6
oma1989 OP @GeruzoniAnsasu 无需注册登录,即可访问的页面中的价格信息,应该算是公开的吧?(没发现有推送渠道)
|
 |
10
xiaoyazi 2019-09-25 11:18:18 +08:00 via iPhone 给你标准答案:
看目标网站用户协议以及有无反扒机制。 如果对方的协议明示不可爬取本站信息并有相应反扒机制,你的行为等同破门而入。 就像公园写着 18 点闭园但大门没关,你进去玩虽不合法但一般都会被原谅,门若关着你爬墙进去就难以辨驳了。 |
|
11
xiaoyazi 2019-09-25 11:18:48 +08:00 via iPhone
所以合不合法不是看高频与否哦
|
 |
13
ccoming 2019-09-25 11:49:01 +08:00 补充问个:高频下载后台提供的报表有风险不?
|
 |
14
qsnow6 2019-09-25 11:52:42 +08:00 “高频”到影响网站正常访问的行为等同于”攻击“
|
 |
15
wangxiaoaer 2019-09-25 11:58:13 +08:00 via Android
听一堆法盲在这指点江山真是有意思。
这种事情去找个律师问下就完了,一些社区服务会有免费资询。 |
|
16
wangxiaoaer 2019-09-25 11:58:58 +08:00 via Android
还什么 robots,反扒等,法律认可这些东西吗?
|
 |
17
hhxx6 2019-09-25 12:00:30 +08:00 via iPhone
robots 只是一种行业的约定吧
根本没有法律效力 貌似 |
|
18
murmur 2019-09-25 12:13:10 +08:00
@wangxiaoaer 反扒这些是不想对簿公堂的时候用的手段
扒东西被起诉能用的罪名多了 |
 |
19
JunoNin 2019-09-25 12:14:51 +08:00 via Android
数据公开怎么定义
|
 |
20
xomix 2019-09-25 12:16:47 +08:00
爬取是不违法的,但是爬取后二次发布是否合法这个就……你自己掂量吧。
|
 |
21
Showfom 2019-09-25 12:19:14 +08:00 via iPhone
就算不违法也违反了网站的使用条款
|


 |
24
Junn 2019-09-25 12:29:27 +08:00
主要看你获取数据的行为方式是否合法,
比如原本是需要注册用户通过账号密码登录获得授权才能获取的数据,你没有账号密码绕过去拿到了,就违法了。 再比如通过接口拿数据的,接口仅供自身 APP 使用,你通过伪造模拟等方式拿到数据,也是违法的。 而比如网站上公开的价格,通过合法方式请求到的数据,只是通过工具爬去节省工作量的行为,应该是不违法的。 当然你的“高频”行为可能涉及到“破坏计算机信息系统罪” |
|
25
GeruzoniAnsasu 2019-09-25 12:36:15 +08:00 via Android
@wangxiaoaer 这种事没法完全依照法律。法律也没有定义爬数据算不算非法盗取计算机数据。公司法务之前还声称只要用户授权,爬个人信息是合法的呢,最近新闻抓进去的搞爬虫的哪个没让用户授权?
数据方 license 的作用是告诉你他不会追责。这才是最管用的。不然照国内的现状,想告你盗数据,怎么的都能把你搞进去 |
 |
26
xiaogui 2019-09-25 12:41:52 +08:00
最近好像很多“做数据”的公司都翻车了,哪怕是公司行为也还是要注意下。
|
|
27
swulling 2019-09-25 12:44:36 +08:00 via iPhone
@Sapp
@dobelee 百度诉 360 爬取判例如下,法院一般会把 robots 认定为行业公认的规则,违反后虽然不一定就违法,但是出于相当不利的地位。 基于以上认定,法院在判决中做出如下认定:“在被告推出搜索引擎伊始,其网站亦刊载了 Robots 协议的内容和设置方法,说明包括被告在内的整个互联网行业对于 Robots 协议都是认可和遵守的。其应当被认定为行业内的通行规则,应当被认定为搜索引擎行业内公认的、应当被遵守的商业道德。被告网站在推出搜索引擎服务之初,为了对原告网站进行抓取以便向网络用户提供最全面的搜索结果,没有遵守行业内公认的、应当被遵守的商业道德,即在被告推出搜索引擎的伊始阶段没有遵守原告网站的 Robots 协议,其行为明显不当,应当承担相应的不利后果。” |
|
28
wangxiaoaer 2019-09-25 12:50:08 +08:00 via Android
@GeruzoniAnsasu 所以我的意思是在这里听一堆法盲拿 robots 等来自己觉得是否违法是一件很可笑的事情。
|
 |
29
mrobot 2019-09-25 13:43:05 +08:00 via iPhone 这其实是一个风险和收益之间的博弈 你爬对方的数据 对方利益受损较小 大概率没事 对方利益受损较大并且发现是你造成的 找你还可以追回部分损失 这时候你是否违法已经不重要了 因为你摊上事了 爬了会所嫩模 不爬下海干活
|
 |
31
dongcxcx 2019-09-25 15:46:19 +08:00
很多网站的开放平台都有接口,通过这种方式获取并使用数据违法吗?
最近好多数据公司都翻车了,感觉谈爬虫色变。。。 |
 |
32
reus 2019-09-25 16:02:26 +08:00
@wangxiaoaer 当然认可,法盲。
|
|
33
reus 2019-09-25 16:05:31 +08:00
@wangxiaoaer http://www.patentexp.com/wp-content/uploads/2014/09/Baidu-v.-Qihoo-2013-Yi-Zhong-Min-Chu-Zi-No.2668.pdf 你自己看看判决,看看法官是怎么看待 robots 协议的。
|
 |
34
justforlook44444 2019-09-25 16:53:03 +08:00
@dobelee 虽然是约定俗称,没有法律效力,但是起码表明了一个事实和态度:我不希望你来爬取我的数据。
|
 |
35
maplelin 2019-09-25 16:57:37 +08:00
@wangxiaoaer #28 按你这么来,开源协议也没写到法律里咯,所以只要代码放到网上就能随便拿来用?
|
 |
36
kisshere 2019-09-25 17:23:46 +08:00 via Android
php 的 file_get_contents 就是史上最不要脸的一个函数
|
 |
37
Greendays 2019-09-25 17:37:43 +08:00
感觉楼上有种观点很有意义。“爬取数据”这种行为法律可能不好判,但是如果爬数据的行为干扰了网站的正常工作,那肯定有办法从别的地方判你违法
|
 |
38
TimePPT 2019-09-25 18:02:51 +08:00
别的不知道,美股行情数据是有版权的,纳斯达克曾经给国内某搜索引擎公司发过律师函,要求每年 400w 美刀使用费。
|
|
39
xiaoyazi 2019-09-25 19:03:30 +08:00 via iPhone
@wangxiaoaer 你又怎么知道别人没咨询过。
|
 |
40
SSW 2019-09-26 15:13:43 +08:00
我记得之前在 v 站看到帖子说今日头条把爬他数据的起诉了
|